创建虚拟控件
在自动化测试中,虚拟控件用于定义界面上的特定区域,使其能够像普通控件一样执行点击、OCR 识别或图像对比等操作。
根据使用场景不同,虚拟控件可通过以下三种方式创建:
| 创建方式 | 说明 | 适用场景 |
|---|---|---|
| 在模型中定义 | 通过模型管理器在模型文件中预定义虚拟控件,可在多个脚本中复用。 | 需要在多个脚本中重复使用的固定控件。 |
| 描述模式创建 | 在脚本中动态指定区域坐标或识别特征,系统即时生成虚拟控件实例。 | 临时处理、动态界面对象,不依赖模型文件。 |
| 控件的虚拟化 | 从已有真实控件直接生成与其区域相同的虚拟控件。 | 需要对整个控件区域进行 OCR 或图像比对时。 |
无论采用哪种方式,虚拟控件在使用上都提供一致的接口,可执行点击、文本识别、截图或图像比对等操作。详细方法请参阅 虚拟控件API。
在模型管理器中创建
在模型管理器中创建虚拟控件是最常用的方式。通过可视化界面,您可以在控件截图上直接绘制虚拟控件区域,也可以在编辑窗口中批量调整多个虚拟控件的属性。这种方式特别适合界面结构稳定、元素布局固定的应用场景。
1. 在截屏上创建虚拟控件
在模型管理器中选中一个已识别的控件后,切换到该控件的截屏页面。 在工具栏中点击 “创建虚拟控件” 按钮,然后在控件截屏区域中拖拽鼠标,即可绘制出虚拟控件的区域。完成绘制后,系统会自动将该区域添加为新的虚拟控件。

这种方式直观快捷,适合在已有控件上快速补充一两个虚拟控件。例如,当控件内包含自绘按钮或图标时,只需为这些区域定义虚拟控件,就可以在测试脚本中直接对它们进行点击或识别。
2. 通过高级编辑器批量创建和调整
若需要一次性编辑多个虚拟控件,可在控件截屏页面点击 “编辑虚拟控件” 打开虚拟控件编辑窗口。 在该窗口中,您可以批量添加、删除或调整虚拟控件,并为每个控件设置名称、对齐方式等属性,从而便于后续脚本调用和界面适配。

通过高级编辑器,您可以在同一视图下统一调整多个虚拟控件的区域与位置,这对于具有动态布局或可缩放窗口的界面尤为方便。
示例场景:自定义图标界面
下面的示例展示了一个名为 appchooser 的 Qt 应用界面。 在该界面中,用户点击某个图标后,该图标会放大并居中显示。为了实现该交互场景的自动化测试,可以通过以下步骤定义虚拟控件:
识别窗体控件
首先,在模型管理器中识别整个窗体控件。例如,该窗体的类型为Custom。 识别后,窗体对象会显示在对象树中,后续的虚拟控件都将隶属于该对象。编辑虚拟控件
在模型管理器中右击已识别的窗体对象,选择 “编辑虚拟控件”,打开虚拟控件编辑窗口。 在编辑窗口中,可以为每个可交互区域定义对应的虚拟控件。
添加并配置虚拟控件
在编辑窗口中,依次执行以下操作:- 添加控件
创建四个虚拟控件,分别命名为Camera、Glass、Ball和Book,对应界面中的四个图标区域。 - 定义区域
使用鼠标框选每个图标对应的区域,确定虚拟控件的矩形边界。 设置对齐方式
为每个虚拟控件指定合适的对齐方式。例如,将Book控件设置为“右下对齐”,这样当窗体大小变化时,该控件仍能准确定位到右下角的“Book”图标。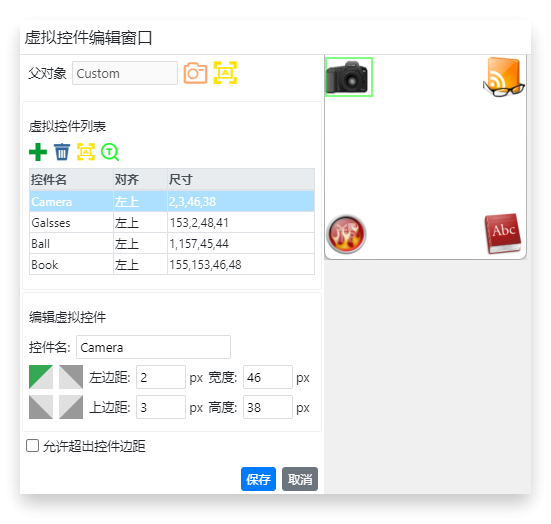
- 添加控件
保存配置
完成编辑后,点击“确定”保存设置。返回模型管理器时,可以看到新增的虚拟控件已出现在对象结构中,作为窗体控件的子节点。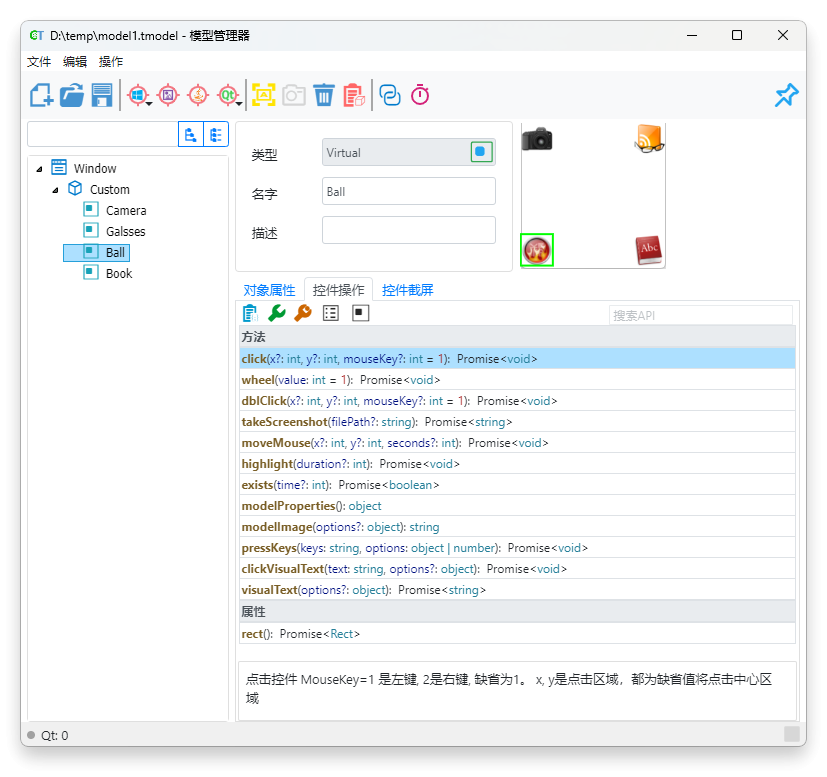
完成上述步骤后,即可在脚本中像操作普通控件一样使用这些虚拟控件。例如:
await model.getVirtual("Camera").click();model.getVirtual("Camera").click()执行脚本时,系统会自动定位并点击 Camera 虚拟控件,无需再计算坐标或进行额外的图像识别,从而简化了脚本编写和维护。
进阶用法:按文字识别与定位
在某些界面中,控件虽然无法被标准方式识别,但其中的文字往往能通过 OCR 技术准确提取。
虚拟控件支持一种基于文字内容的定位方式,只需在标识属性中添加 text 属性,即可根据文字内容自动查找并定位目标区域。
工作原理
当虚拟控件包含 text 属性时,工具会执行以下流程:
- 在该虚拟控件的区域内调用
textItems(),识别所有文本块; - 遍历识别出的文本内容,并筛选出与
text属性值匹配的项; - 默认返回第一个匹配的虚拟控件实例。
若希望同时获取多个匹配结果,可以调用 all() 方法,以返回所有符合条件的文本块对应的虚拟控件列表。
使用示例
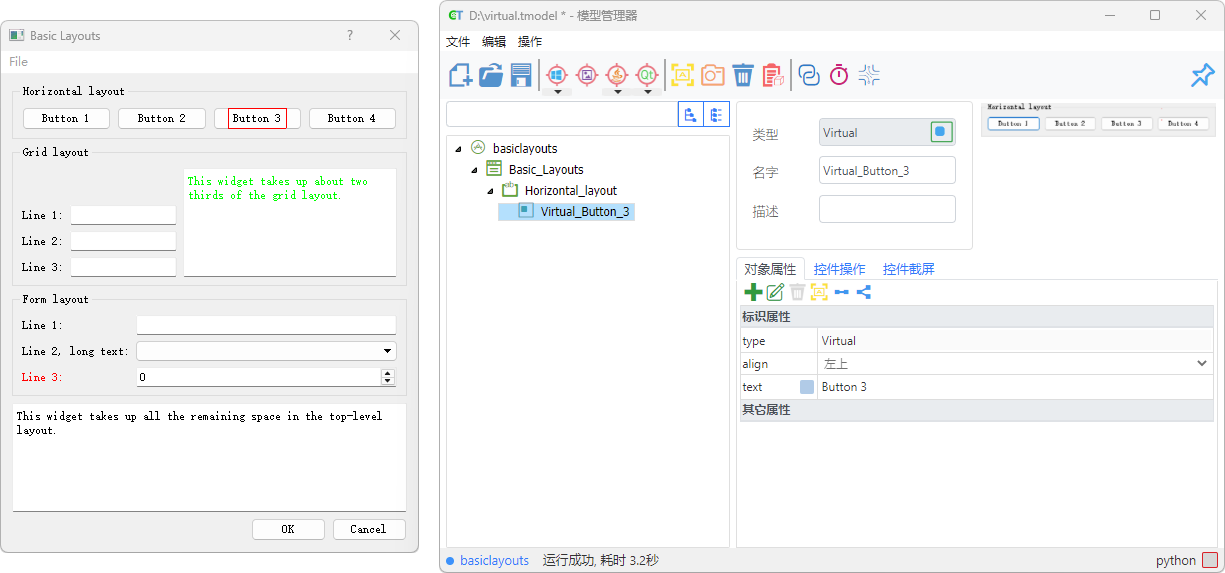
下面的示例展示了如何将一个控件虚拟化,并通过 text 属性获取所有包含“Button”文本的区域,然后依次执行操作:
// 1. 操作模型中已定义的虚拟控件
await model.getVirtual("Virtual_Button_3").highlight()
// 2. 在已有虚拟控件的基础上,覆盖或补充识别属性
await model.getVirtual("Virtual_Button_3", { "text": "Button 3" }).highlight();
// 3. 将控件虚拟化后,获取所有包含“Button”文字的文本块,并依次高亮
let buttons = await model.getGeneric("Horizontal_layout").getVirtual({ "text": "Button" }).all();
for (const btn of buttons) {
await btn.highlight();
}# 1. 直接操作模型中已定义的虚拟控件
model.getVirtual("Virtual_Button_3").highlight()
# 2. 在已有虚拟控件的基础上,覆盖或补充识别属性
model.getVirtual("Virtual_Button_3", { "text": "Button 3" }).highlight()
# 3. 将控件虚拟化后,查找所有包含“Button”的文本块并依次高亮
buttons = model.getGeneric("Horizontal_layout").getVirtual({ "text": "Button" }).all()
for btn in buttons:
btn.highlight()适用场景
基于文字的虚拟控件查找在以下情况下尤其有用:
- 自绘或非标准控件无法被直接识别,但文字内容稳定可见;
- 需要批量处理多个相似的文本元素(例如一组按钮、标签或菜单项);
- OCR 识别准确、文字布局规则的界面;
这种方式能够在不修改模型结构的前提下,实现灵活的文字定位与批量操作,兼顾可维护性与动态适应性。