Pytest-BDD使用指南
CukeTest 为 pytest-bdd 提供了内置支持,显著提升了开发效率。它不仅支持 Gherkin 步骤与 Python 代码之间的双向跳转,还可为未实现的步骤自动生成函数框架,帮助您专注于编写业务逻辑。与此同时,CukeTest 还提供丰富的项目模板和示例,让您无论是刚入门还是已经熟练,都能快速上手并充分发挥 pytest-bdd 的优势。
Pytest-BDD 是一个实现了行为驱动开发(BDD)的 Python 测试库。它将 pytest 测试框架与自然语言描述的 Gherkin 语法巧妙结合,为 Python 项目提供了一种清晰、直观且高效的测试解决方案。
与其他 BDD 工具相比,pytest-bdd 的一个显著优势是它无需专门的测试运行器。它作为一个 pytest 插件运行,与 pytest 的生态系统无缝集成。这意味着您可以将 BDD 功能测试与传统的单元测试、集成测试放在同一个测试套件中执行,从而简化了持续集成(CI)的配置,并促进了测试代码的重用。
pytest-bdd 的核心魅力在于其对 pytest fixtures 的巧妙运用。您为单元或集成测试编写的 pytest fixtures(即测试的预置条件、环境和数据),可以通过依赖注入的方式直接在 BDD 的步骤定义函数中使用。这种设计哲学带来了诸多好处:
- 代码重用: 大幅减少了重复的设置(setup)和清理(teardown)代码。
- 避免全局上下文: 无需依赖一个在步骤间共享状态的全局 "context" 对象,让测试用例更加独立、健壮且易于维护。
- 声明式测试: 步骤函数清晰地声明其所需的依赖,而不是通过命令式的代码来构建状态,这使得测试的意图更加明确。
简而言之,pytest-bdd 允许您使用接近自然语言的 Gherkin 语法来描述软件的行为和需求。这些描述不仅是测试用例,更是项目的“活文档”,能够促进开发者、测试人员和非技术背景的业务人员之间的沟通与协作,确保软件开发与业务目标保持一致。
例子
这是一个测试博客托管软件的示例:
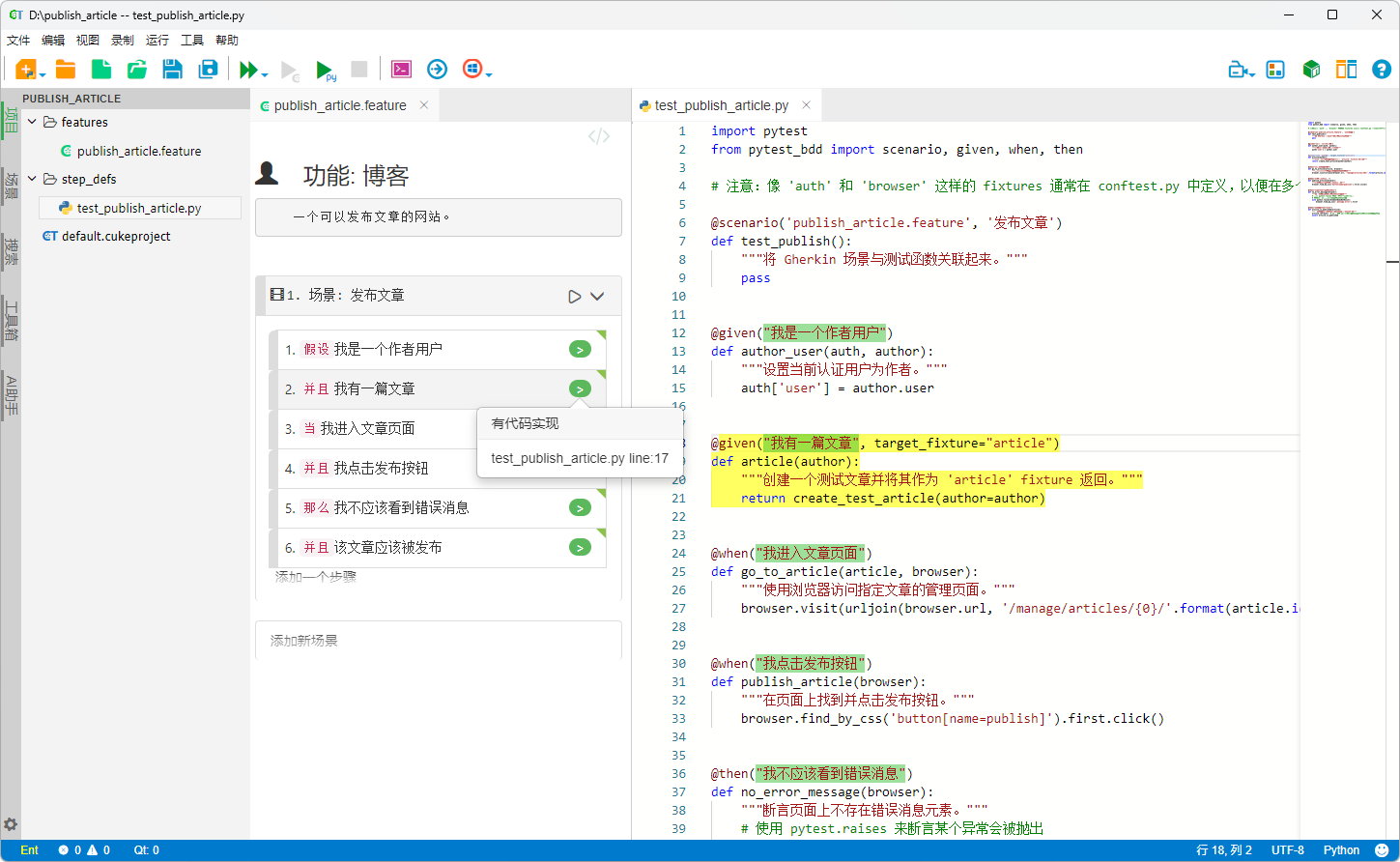
# language: zh-CN
# publish_article.feature 的内容
功能: 博客
一个可以发布文章的网站。
场景: 发布文章
假设我是一个作者用户
并且我有一篇文章
当我进入文章页面
并且我点击发布按钮
那么我不应该看到错误消息
并且该文章应该被发布 # 备注: 将查询数据库
请注意,每个
.feature文件中建议只定义一个功能(Feature)。虽然一个功能下可以包含多个场景(Scenario),但将不同的核心功能分散到不同的文件中,可以使每个文件的主题更明确、更专注,从而提高测试用例的可读性和可维护性。
以下是与上述 .feature 文件对应的 Python 测试代码。这些代码通常保存在一个以 test_ 开头的 .py 文件中,例如 test_publish_article.py。
# test_publish_article.py 的内容
import pytest
from pytest_bdd import scenario, given, when, then
# 注意:像 'auth' 和 'browser' 这样的 fixtures 通常在 conftest.py 中定义,以便在多个测试文件中共享。
@scenario('publish_article.feature', '发布文章')
def test_publish():
"""将 Gherkin 场景与测试函数关联起来。"""
pass
@given("我是一个作者用户")
def author_user(auth, author):
"""设置当前认证用户为作者。"""
auth['user'] = author.user
@given("我有一篇文章", target_fixture="article")
def article(author):
"""创建一个测试文章并将其作为 'article' fixture 返回。"""
return create_test_article(author=author)
@when("我进入文章页面")
def go_to_article(article, browser):
"""使用浏览器访问指定文章的管理页面。"""
browser.visit(urljoin(browser.url, '/manage/articles/{0}/'.format(article.id)))
@when("我点击发布按钮")
def publish_article(browser):
"""在页面上找到并点击发布按钮。"""
browser.find_by_css('button[name=publish]').first.click()
@then("我不应该看到错误消息")
def no_error_message(browser):
"""断言页面上不存在错误消息元素。"""
# 使用 pytest.raises 来断言某个异常会被抛出
# 这意味着我们期望找不到错误消息元素
with pytest.raises(ElementDoesNotExist):
browser.find_by_css('.message.error').first
@then("该文章应该被发布")
def article_is_published(article):
"""检查文章对象的状态是否已更新为'已发布'。"""
article.refresh() # 对于 ORM 对象,可能需要刷新以从数据库获取最新状态
assert article.is_publishedscenario 装饰器
@scenario 装饰器用于将一个测试函数与 .feature 文件中的特定场景进行绑定。
通常,这个被装饰的测试函数本身不需要包含任何代码(使用 pass 即可),因为所有的测试逻辑都由 given, when, then 步骤函数来执行。不过,您也可以在该函数中编写代码,这些代码会在该场景的所有步骤都成功执行 之后 运行,通常用于最终的断言或清理工作。
from pytest_bdd import scenario, given, when, then
@scenario('publish_article.feature', '发布文章')
def test_publish(browser, article):
"""测试函数体会在所有步骤执行后运行。"""
# 示例:检查文章标题是否出现在最终的页面中
assert article.title in browser.html
最佳实践:我们强烈建议将所有的测试逻辑都放在
given、when、then步骤中。这能让您的测试场景更加结构化,与 Gherkin 文件中的描述一一对应,从而提高可读性和可维护性。
步骤别名
在不同的场景中,您可能会用不同的措辞来描述同一个操作。为了避免代码重复,pytest-bdd 允许您为同一个步骤函数绑定多个别名。只需为同一个函数添加多个步骤装饰器即可。
@given("我有一篇文章")
@given("有一篇文章")
def article(author):
"""这个函数同时实现了'我有一篇文章'和'有一篇文章'这两个步骤。"""
return create_test_article(author=author)这种做法非常有用。例如,某个场景描述的是特定作者创建文章,而另一个场景描述的是系统中的任意一篇文章,但底层的准备逻辑是相同的。
# language: zh-CN
功能: 资源所有者
场景: 我是作者
假设我是一个作者
并且我有一篇文章 # <-- 匹配 @given("我有一篇文章")
场景: 我是管理员
假设我是管理员
并且有一篇文章 # <-- 匹配 @given("有一篇文章")
通过步骤别名,您可以用更符合自然语言习惯的方式编写场景,同时保持后端代码的简洁和高效。
使用星号代替关键字
为了让 Gherkin 场景的表达更流畅,避免重复使用 并且(And)或 但是(But)等连接词,您可以使用星号(*)来代替。
星号(*)的行为会继承自前一个非星号的关键字。例如,如果 * 跟在 假设(Given)后面,它也会被当作一个 Given 步骤。
这种写法可以使连续的同类型步骤看起来更简洁、更像一个列表。
示例:
# language: zh-CN
功能: 资源拥有者
场景: 我是作者
假如 我是一个作者
* 我有一篇文章
* 我有一支笔
对应的步骤定义代码与常规写法完全相同:
from pytest_bdd import given
@given("我是一个作者")
def _():
pass
@given("我有一篇文章")
def _():
pass
@given("我有一支笔")
def _():
pass在上面的 Gherkin 示例中,* 我有一篇文章 和 * 我有一支笔 都会被 pytest-bdd 解释为 given 步骤。当您需要罗列一系列前提条件(Given)、操作(When)或断言(Then)时,使用星号是一种非常实用的技巧,它能有效提升场景的可读性。
步骤参数
通常可以通过给步骤添加参数来重用步骤。这样可以一次实现,多次使用,从而减少代码量。还可以在单个场景中两次使用相同的步骤并使用不同的参数。此外,还有几种类型的步骤参数解析器可供使用 (灵感来自 behave 框架的实现):
string (默认)
这是默认值,可以视为null或exact解析器。它不解析参数,并通过字符串相等来匹配步骤名称。
parse (基于: pypi_parse)
提供了一个简单的解析器,用类似 {param:Type} 的可读语法取代步骤参数的正则表达式。该语法受 Python 内置的 string.format() 函数启发。步骤参数必须在步骤定义中使用 pypi_parse 的命名字段语法。命名字段会被提取出来,可选择进行类型转换,然后用作步骤函数参数。支持通过extra_types传递的类型转换器进行类型转换。
cfparse (扩展: pypi_parse, 基于: pypi_parse_type)
提供了一个带有“Cardinality Field”(CF)支持的扩展解析器。只要为 cardinality=1 提供了类型转换器,就会自动创建相关基数的缺失类型转换器。支持像这样的解析表达式:
{values:Type+}(cardinality=1..N, 1到多){values:Type*}(cardinality=0..N, 0到多){value:Type?}(cardinality=0..1, 可选)
支持类型转换(如上)。
re
这将使用完整的正则表达式来解析子句文本。你需要使用命名分组 (?P<name>...) 来定义从文本中提取并传递给 step() 函数的变量。类型转换只能通过 converters step 装饰器参数完成(见下面的示例)。
默认解析器是 string,因此只需一对一匹配关键字定义。
除 string 以外的解析器及其可选参数的指定方式如下:
对于cfparse解析器
from pytest_bdd import parsers
@given(
parsers.cfparse("那里有{start:Number}根黄瓜", extra_types={"Number": int}),
target_fixture="cucumbers",
)
def given_cucumbers(start):
return {"start": start, "eat": 0}对于re解析器
from pytest_bdd import parsers
@given(
parsers.re(r"那里有(?P<start>\d+)根黄瓜"),
converters={"start": int},
target_fixture="cucumbers",
)
def given_cucumbers(start):
return {"start": start, "eat": 0}例子:
# language: zh-CN
功能: 步骤参数测试
场景: 在假如、当、那么步骤中使用参数
假如那里有5根黄瓜
当我吃了3根黄瓜
并且我吃了2根黄瓜
那么我应该有0根黄瓜
代码如下所示:
from pytest_bdd import scenarios, given, when, then, parsers
scenarios("arguments.feature")
@given(parsers.parse("那里有{start:d}根黄瓜"), target_fixture="cucumbers")
def given_cucumbers(start):
return {"start": start, "eat": 0}
@when(parsers.parse("我吃了{eat:d}根黄瓜"))
def eat_cucumbers(cucumbers, eat):
cucumbers["eat"] += eat
@then(parsers.parse("我应该有{left:d}根黄瓜"))
def should_have_left_cucumbers(cucumbers, left):
assert cucumbers["start"] - cucumbers["eat"] == left示例代码还显示了传递参数转换器的可能性,如果你需要在解析器之后对步骤参数进行后处理,这可能会很有用。
你可以实现自己的步骤解析器。它的接口非常简单。代码可以如下所示:
import re
from pytest_bdd import given, parsers
class MyParser(parsers.StepParser):
"""Custom parser."""
def __init__(self, name, **kwargs):
"""Compile regex."""
super().__init__(name)
self.regex = re.compile(re.sub("%(.+)%", "(?P<\1>.+)", self.name), **kwargs)
def parse_arguments(self, name):
"""Get step arguments.
:return: `dict` of step arguments
"""
return self.regex.match(name).groupdict()
def is_matching(self, name):
"""Match given name with the step name."""
return bool(self.regex.match(name))
@given(parsers.parse("那里有%start%根黄瓜"), target_fixture="cucumbers")
def given_cucumbers(start):
return {"start": start, "eat": 0}通过given步骤覆盖 fixture
依赖注入并不是万能的,特别是你的测试设置数据结构复杂的时候。有时,需要这样一个给定步骤,即只在特定测试(场景)中必须更改 fixture,而在其他测试中则保持不变。为此,在 given装饰器中存在一个特殊参数 target_fixture(目标测试夹具):
from pytest_bdd import given
@pytest.fixture
def foo():
return "foo"
@given("我有一个注入的given", target_fixture="foo")
def injecting_given():
return "injected foo"
@then('注入foo的值应该是"injected foo"')
def foo_is_foo(foo):
assert foo == 'injected foo'# language: zh-CN
功能: 目标测试夹具功能
场景: 测试given夹具注入
假如我有一个注入的given
那么注入foo的值应该是"injected foo"
在这个例子中,现有的 fixture foo 将被 given 步骤 我有一个注入的given 覆盖。
有时,让 when 和 then步骤提供 fixture 也很有用。一个常见的用例是我们必须断言 HTTP 请求的结果:
# test_blog.py的内容
from pytest_bdd import scenarios, given, when, then
from my_app.models import Article
scenarios("blog.feature")
@given("有一篇博客文章", target_fixture="article")
def there_is_an_article():
return Article()
@when("我请求删除这篇博客文章", target_fixture="request_result")
def there_should_be_a_new_article(article, http_client):
return http_client.delete(f"/articles/{article.uid}")
@then("这个请求应该成功")
def article_is_published(request_result):
assert request_result.status_code == 200# language: zh-CN
# blog.feature的内容
功能: 博客功能测试
场景: 删除博客文章
假如有一篇博客文章
当我请求删除这篇博客文章
那么这个请求应该成功
场景快捷方式
如果你有一组相对较大的 feature 文件,那么使用场景装饰器手动将场景绑定到测试会很繁琐。当然,使用手动方法,你可以定制额外参数化测试,为测试函数命名,记录它等,但在大多数情况下并不需要这样做。相反,你希望通过使用 scenarios 来自动递归绑定在 features 文件夹中找到的所有场景。
from pytest_bdd import scenarios
# 假设“features”子文件夹位于该文件的目录中
scenarios('features')这就是你需要做的所有事情,以绑定在 features 文件夹中找到的所有场景!请注意,你可以传递多个路径,这些路径可以是feature文件或feature文件夹。
from pytest_bdd import scenarios
# 传递多个路径/文件
scenarios('features', 'other_features/some.feature', 'some_other_features')但如果你需要手动绑定某个场景,而让其他场景自动绑定怎么办?只需以通常的方式编写你的场景绑定,且确保这个代码放置在scenarios函数之前:
from pytest_bdd import scenario, scenarios
@scenario('features/some.feature', 'Test something')
def test_something():
pass
# 假设“features”子文件夹位于该文件的目录中
scenarios('features')test_something场景将保持手动绑定,features文件夹中找到的其他场景将自动绑定。
场景大纲
场景可以参数化以覆盖多种情况。这些在 Gherkin 中称为场景大纲,变量模板使用尖括号编写(例如
例子:
# language: zh-CN
# scenario_outlines.feature的内容
功能: 场景大纲应用
场景大纲: 再场景大纲中使用假如、当、那么
假如那里有<start>根黄瓜
当我吃了<eat>根黄瓜
那么我应该有<left>根黄瓜
例子:
| start | eat | left |
| 12 | 5 | 7 |
from pytest_bdd import scenarios, given, when, then, parsers
scenarios("scenario_outlines.feature")
@given(parsers.parse("那里有{start:d}根黄瓜"), target_fixture="cucumbers")
def given_cucumbers(start):
return {"start": start, "eat": 0}
@when(parsers.parse("我吃了{eat:d}根黄瓜"))
def eat_cucumbers(cucumbers, eat):
cucumbers["eat"] += eat
@then(parsers.parse("我应该有{left:d}根黄瓜"))
def should_have_left_cucumbers(cucumbers, left):
assert cucumbers["start"] - cucumbers["eat"] == left示例表格中的参数不仅可以用于步骤语句中,也可以直接嵌入到文档字符串(docstring)和数据表(datatable)中,从而实现动态替换,这为需要复杂设置或验证的场景提供了额外的灵活性。
例子:
# language: zh-CN
# docstring_and_datatable_with_params.feature 文件内容
功能: 使用示例参数的文档字符串和数据表
场景大纲: 在文档字符串和数据表中使用参数
假如用户登录信息如下:
"""
username: <username>
password: <password>
"""
当用户登录
那么响应结果应包含:
| field | value |
| username | <username> |
| logged_in | true |
例子:
| username | password |
| user1 | pass123 |
| user2 | 123secure |
from pytest_bdd import scenarios, given, when, then
import json
# 从 feature 文件中加载场景
scenarios("docstring_and_datatable_with_params.feature")
@given("用户登录信息如下:")
def given_user_config(docstring):
print(docstring)
@when("用户登录")
def user_logs_in(logged_in):
logged_in = True
@then("响应结果应包含:")
def response_should_contain(datatable):
assert datatable[1][1] in ["user1", "user2"]使用多个示例表的场景大纲
在 pytest-bdd 中,你可以在一个场景大纲中使用多个示例表,以便在不同条件下测试多组输入数据。
你可以定义多个示例块,每个块都有自己的数据表,并且可以通过标签tag区分,比如正向用例、负向用例或其他测试条件。
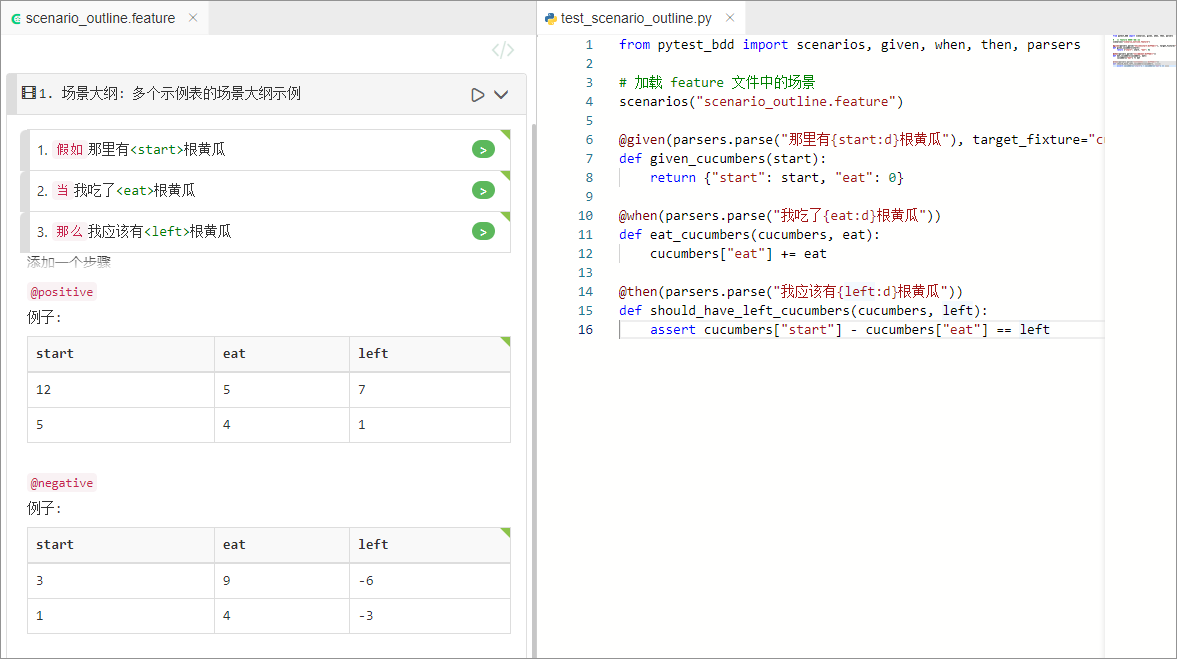
# language: zh-CN
# scenario_outline.feature 文件内容
功能: 使用多个示例表的场景大纲
场景大纲: 多个示例表的场景大纲示例
假如那里有<start>根黄瓜
当我吃了<eat>根黄瓜
那么我应该有<left>根黄瓜
@positive
例子: 正向结果
| start | eat | left |
| 12 | 5 | 7 |
| 5 | 4 | 1 |
@negative
例子: 不可能的负向结果
| start | eat | left |
| 3 | 9 | -6 |
| 1 | 4 | -3 |
from pytest_bdd import scenarios, given, when, then, parsers
# 加载 feature 文件中的场景
scenarios("scenario_outline.feature")
@given(parsers.parse("那里有{start:d}根黄瓜"), target_fixture="cucumbers")
def given_cucumbers(start):
return {"start": start, "eat": 0}
@when(parsers.parse("我吃了{eat:d}根黄瓜"))
def eat_cucumbers(cucumbers, eat):
cucumbers["eat"] += eat
@then(parsers.parse("我应该有{left:d}根黄瓜"))
def should_have_left_cucumbers(cucumbers, left):
assert cucumbers["start"] - cucumbers["eat"] == left当你使用标签过滤场景时,只有与该标签相关联的示例表会被执行。这使你可以根据标签选择性地运行测试用例的某个子集。
例如,在上面的场景大纲中,如果你按 @positive 标签进行过滤,只有“正向结果”表下的示例会被执行,而“负向结果”表下的示例将被忽略。
pytest -k "positive"
处理示例表中的空单元格
在默认情况下,示例表中的空单元格会被解析为一个空字符串。然而,在某些情况下,将其处理为None更合适。
此时可以使用带有parsers.re解析器的转换器(converter),为空值定义自定义行为。
例如,下面的代码演示了如何使用一个自定义转换器,在遇到空单元格时返回 None:
# language: zh-CN
# 文件:empty_example_cells.feature
功能: 处理空示例单元格
场景大纲: 使用转换器处理空单元格
当我开始午餐
那么有<start>根黄瓜
例子:
| start |
| |
from pytest_bdd import then, parsers
# 定义一个转换器,将空字符串转换为 None
def empty_to_none(value):
return None if value.strip() == "" else value
@given("我开始午餐")
def _():
pass
@then(parsers.re("有(?P<start>.*?)根黄瓜"), converters={"start": empty_to_none})
def _(start):
# 示例断言,用于展示转换效果
assert start is None
在这个例子中,示例表格中的start单元格为空。当装饰器中的parsers.re与empty_to_none转换器配合使用时,这个空单元格会被转换为None,这样就可以在步骤定义中以 None的方式处理它了。
规则
在Gherkin语言中,规则(Rules)用于在一个共享上下文(shared context)中将相关的场景或示例进行分组,这在为一组结构类似的用例定义不同的条件或行为时有所帮助。
你可以使用场景或例子来定义各个用例,它们是等价的别名,功能上没有区别。
此外,应用于规则的标签(tags) 会自动应用到该规则下的所有场景或例子上,这使得在测试执行过程中组织和筛选变得更加方便。
# language: zh-CN
功能: 规则与示例的使用
@feature_tag
规则: 针对有效用例的规则
@rule_tag
例子: 有效用例1
假如我输入了一个有效的值
当我处理这个输入时
那么结果应为成功
规则: 针对无效用例的规则
例子: 无效用例
假如我输入了一个无效的值
当我处理这个输入时
那么结果应为错误
数据表
datatable参数允许你在测试函数中直接使用场景中定义的数据表。这对于需要以表格形式输入数据的场景尤其有用,可以方便地管理和操作这些数据。
当你在步骤定义中使用datatable参数时,它会将数据表返回为一个列表的列表,其中每个内层列表代表数据表中的一行。
例如,对于下方的数据表:
| name | email |
| John | john@example.com |
会通过datatable参数返回为:
[
["name", "email"],
["John", "john@example.com"]
]注意:
使用datatable参数时,如果步骤中没有数据表却尝试使用datatable参数时会引发报错。因此需确保每个使用datatable参数的步骤均正确定义并引用了数据表。
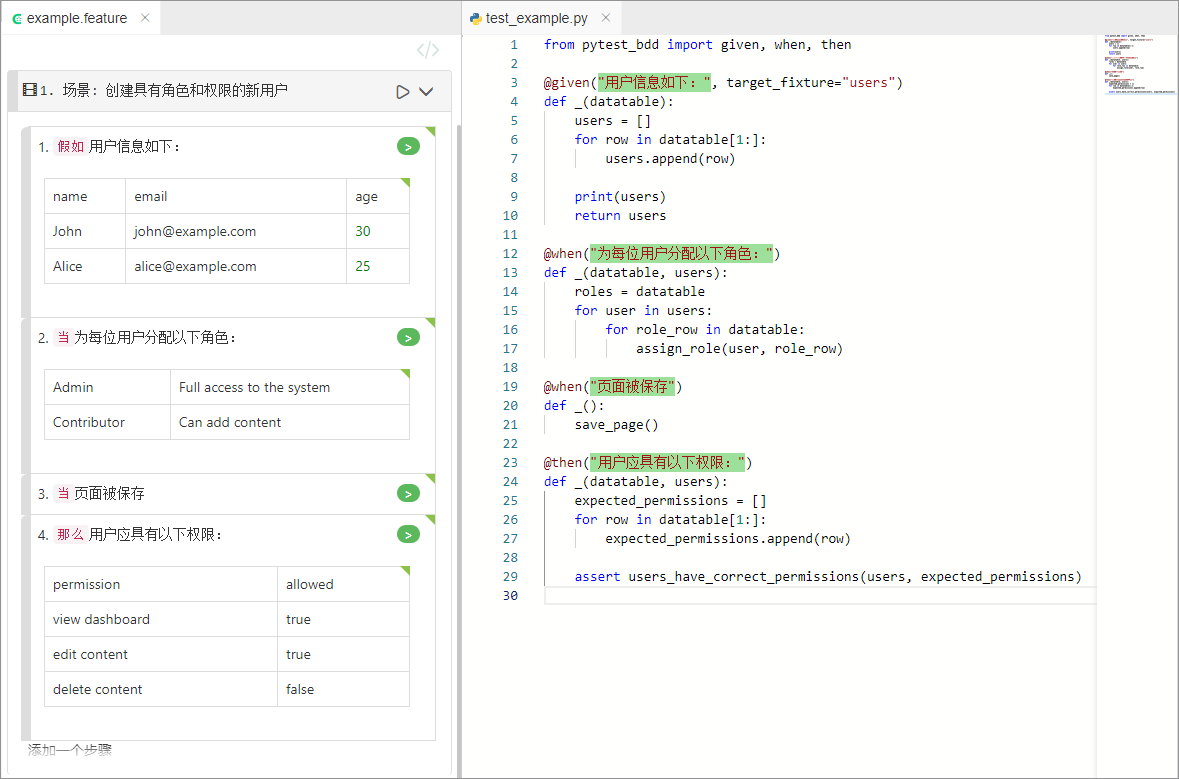
例子:
# language: zh-CN
功能: 管理用户账号
场景: 创建具有角色和权限的新用户
假如用户信息如下:
| name | email | age |
| John | john@example.com | 30 |
| Alice | alice@example.com | 25 |
当为每位用户分配以下角色:
| Admin | Full access to the system |
| Contributor | Can add content |
当页面被保存
那么用户应具有以下权限:
| permission | allowed |
| view dashboard | true |
| edit content | true |
| delete content | false |
from pytest_bdd import given, when, then
@given("用户信息如下:", target_fixture="users")
def _(datatable):
users = []
for row in datatable[1:]:
users.append(row)
print(users)
return users
@when("为每位用户分配以下角色:")
def _(datatable, users):
roles = datatable
for user in users:
for role_row in datatable:
assign_role(user, role_row)
@when("页面被保存")
def _():
save_page()
@then("用户应具有以下权限:")
def _(datatable, users):
expected_permissions = []
for row in datatable[1:]:
expected_permissions.append(row)
assert users_have_correct_permissions(users, expected_permissions)
多行字符串
在Gherkin语言中,docstring参数允许你以多行字符串的形式访问步骤中定义的文档字符串。该字符串内容会作为一个整体字符串传入,并以\\n分隔每一行,开头的缩进将会被自动去除。
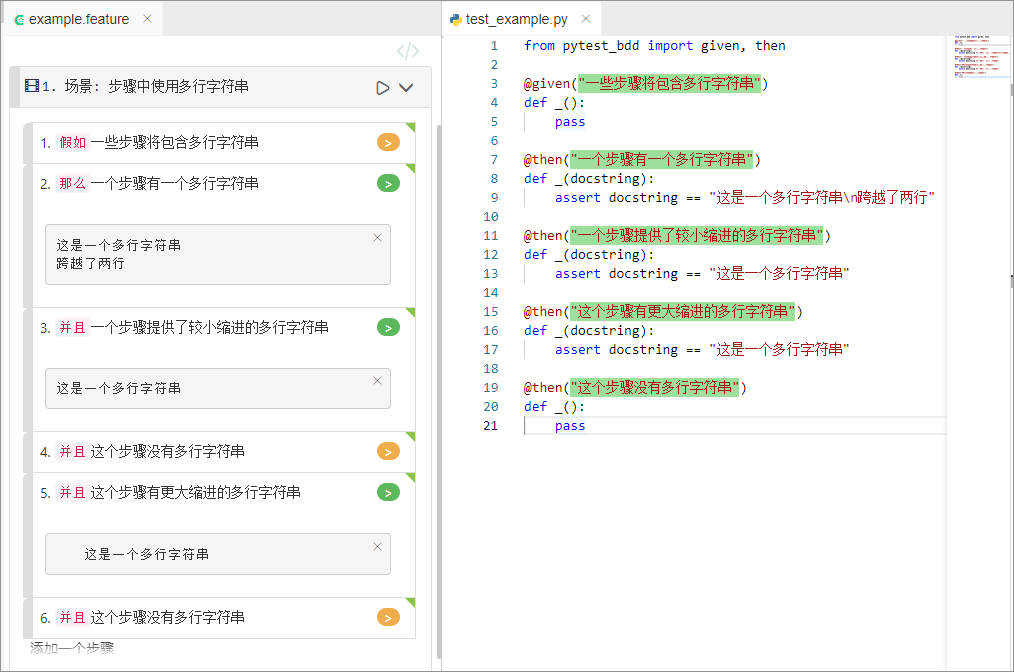
例子:
"""
这是一个多行字符串的例子。
它被扩展为多行形式。
"""
如上形式将会被解析为:
"这是一个多行字符串的例子。\n它被扩展为多行形式。"完整用例:
# language: zh-CN
功能: 多行字符串示例
场景: 步骤中使用多行字符串
假如一些步骤将包含多行字符串
那么一个步骤有一个多行字符串
"""
这是一个多行字符串
跨越了两行
"""
并且一个步骤提供了较小缩进的多行字符串
"""
这是一个多行字符串
"""
并且这个步骤没有多行字符串
并且这个步骤有更大缩进的多行字符串
"""
这是一个多行字符串
"""
并且这个步骤没有多行字符串
对应的 Python 实现:
from pytest_bdd import given, then
@given("一些步骤将包含多行字符串")
def _():
pass
@then("一个步骤有一个多行字符串")
def _(docstring):
assert docstring == "这是一个多行字符串\n跨越了两行"
@then("一个步骤提供了较小缩进的多行字符串")
def _(docstring):
assert docstring == "这是一个多行字符串"
@then("这个步骤有更大缩进的多行字符串")
def _(docstring):
assert docstring == "这是一个多行字符串"
@then("这个步骤没有多行字符串")
def _():
pass注意:只有当步骤实际包含一个多行字符串时,docstring参数才能使用,否则会抛出错误。
管理你的场景
你拥有的 features 和 scenarios 越多,管理它们就变得越重要。你可以通过以下方式组织你的场景:
- 按语义组组织文件夹中的 feature 文件:
features
│
├──frontend
│ │
│ └──auth
│ │
│ └──login.feature
└──backend
│
└──auth
│
└──login.feature
这看起来不错,但是如何只针对某个 feature 运行测试呢?由于 pytest-bdd 使用 pytest,bdd 场景实际上是正常的测试。但测试文件与 feature 文件是分开的,映射由开发人员决定,因此测试文件结构可能看起来完全不同:
tests
│
└──functional
│
└──test_auth.py
│
└ """Authentication tests."""
from pytest_bdd import scenario
@scenario('frontend/auth/login.feature')
def test_logging_in_frontend():
pass
@scenario('backend/auth/login.feature')
def test_logging_in_backend():
pass
# language: zh-CN
@login @backend
功能: 登录功能
@successful
场景: 成功登录
pytest-bdd 使用 pytest markers 作为给定场景测试场景的标签存储,因此我们可以使用标准测试选择方式:
pytest -m "backend and login and successful"
feature 和 scenario 标签与标准 pytest markers 没有什么不同,并且@符号会自动删除以允许测试选择器表达式。如果你希望 bdd 相关的标签与其他测试标记区分开来,请使用 bdd 这样的前缀。请注意,如果你将 pytest 与该 --strict-markers 选项一起使用,则 feature 文件中提到的所有 bdd 标签也应该出现在 pytest.ini 配置的 markers 设置中。另外,对于标签,请使用与 python 兼容的变量名,即以非数字开头,仅下划线或字母数字字符等。这样你就可以正确地使用标签进行测试过滤。
通过实现 pytest_bdd_apply_tag 钩子并返回 True,你可以自定义如何将标记转换为 pytest 标记:
def pytest_bdd_apply_tag(tag, function):
if tag == 'todo':
marker = pytest.mark.skip(reason="Not implemented yet")
marker(function)
return True
else:
# pytest-bdd 的默认行为
return None
测试设置
测试设置在 Given 部分中实现。尽管这些步骤是强制执行的,以应用可能的副作用,但 pytest-bdd 正在尝试利用基于依赖项注入的 PyTest fixture ,并使设置更具声明性。
@given("我有一篇漂亮的文章", target_fixture="article")
def article():
return Article(is_beautiful=True)目标 PyTest 装置"article"将获取返回值,任何其他步骤都可以使用它。
# language: zh-CN
功能: PyTest 的强大功能
场景: 步骤间共享的符号名称
假如我有一篇漂亮的文章
当我发布这篇文章
这里 When 的步骤会获得 article 的值并执行 publish()。
@when("我发布这篇文章")
def publish_article(article):
article.publish()许多其他 BDD 工具包在全局上下文中运行并产生全局副作用。这使得实现这些步骤变得非常困难,因为依赖项仅作为运行时的副作用出现,而不是在代码中声明。"publish article" 步骤必须相信 article 已经在上下文中,必须知道它存储在那里的属性的名称、类型等。
在 pytest-bdd 中,你只需声明它所依赖的步骤函数的参数,PyTest 将确保提供它。
通过 BDD 的设计,仍然可以以命令式方式应用副作用。
# language: zh-CN
功能: 新闻网站
场景: 发布一篇文章
假如我有一篇漂亮的文章
并且我的文章已被发布
功能测试可以重复使用为单元测试创建的 fixture 库,并通过应用副作用对其进行修改。
@pytest.fixture
def article():
return Article(is_beautiful=True)
@given("我有一篇漂亮的文章")
def i_have_a_beautiful_article(article):
pass
@given("我的文章已被发布")
def published_article(article):
article.publish()
return article通过这种方式,副作用被应用到我们的 article 中,PyTest 确保需要 "article" fixture 的所有步骤都将收到相同的对象。"published_article" 和 "article" fixture的值是相同的对象。
fixture在 PyTest 范围内仅计算一次,并且它们的值被缓存。
背景
通常情况下,要覆盖某些功能,你需要多个场景。而且这些场景的初始化通常会有一些共用的部分。为此,有了 Background 这个概念。pytest-bdd 实现了Gherkin 背景的 feature。
# language: zh-CN
功能: 多站点支持
背景:
假如有一位名叫"Greg"的全局管理员
并且有一个名为"Greg的日记"的博客
并且有一位名叫"Wilson"的客户
并且有一个名为"昂贵疗法"的博客,属于"Wilson"
场景: Wilson发表在自己的博客上
假如我以Wilson的身份登录
当我尝试发布到"昂贵疗法"
那么我应该看到"您的文章已发布。"
场景: Greg发表在客户的博客上
假如我以Greg的身份登录
当我尝试发布到"昂贵疗法"
那么我应该看到"您的文章已发布。"
在这个例子中,所有来自背景的步骤都将在所有场景自己的步骤之前执行,为多个场景在单个功能中准备一些共同设置提供了可能性。关于背景的最佳实践,请阅读Gherkin的 背景使用技巧。
在
背景部分中只能使用假如步骤。禁止使用当和那么步骤,因为它们的目的与行动和结果相关;这与背景的目标相冲突——准备系统进行测试或“将系统置于已知状态”,如假如所做的那样。上面的语句适用于严格的Gherkin模式,该模式默认启用。
重复利用fixture
有时场景会为现有的fixture定义可以继承(重用)的新名称。例如,如果我们有pytest fixture:
@pytest.fixture
def article():
"""返回测试文章."""
return Article()然后可以使用 given() 将该 fixture 与其他名称一起重用:
@given('我有一篇漂亮的文章')
def i_have_an_article(article):
"""我有一篇漂亮的文章。"""重复使用步骤
在父 conftest.py 中定义一些公共步骤,然后在子测试文件中简单地期望它们是可行的。
# common_steps.feature的内容
场景: 所有步骤都在conftest中声明
假如我有一个名为bar的测试夹具
那么测试夹具bar的值应该是"bar"
# conftest.py的内容
from pytest_bdd import given, then
@given("我有一个名为bar的测试夹具", target_fixture="bar")
def bar():
return "bar"
@then('测试夹具bar的值应该是"bar"')
def bar_is_bar(bar):
assert bar == "bar"# test_common.py的内容
@scenario("common_steps.feature", "所有步骤都在conftest中声明")
def test_conftest():
pass测试文件中没有步骤的定义。它们是从父 conftest.py 收集的。
默认步骤
以下是在pytest-bdd内部实现的步骤:
假如(given)
- trace:通过
pytest.set_trace()进入pdb调试器
当(when)
- trace:通过
pytest.set_trace()进入pdb调试器
那么(then)
- trace: 通过
pytest.set_trace()进入pdb调试器
在pytest-bdd中,不论是假如、当还是那么步骤,都提供了一个名为trace的默认步骤。当你在Gherkin语法的feature文件中使用该步骤时,它会触发pdb调试器。这意味着,无论在哪个阶段,当你需要对某一步进行调试时,都可以利用这个trace步骤方便地进入调试模式。
如果你想在某个特定的步骤中进行调试,可以采用以下方法:
1.在feature文件中插入trace步骤
在你想要进行调试的地方,无论是在假如、当还是那么段落,加入trace步骤。例如:
# language: zh-CN
功能: 某个功能的描述
场景: 某个场景的描述
假如一些初始条件
当我执行某个操作
那么trace
并且我期望某个结果
2.运行测试
使用命令行运行你的测试。你可以使用标准的pytest命令,例如:
pytest path_to_your_test_file.py
3.开始调试
当测试运行到trace步骤时,它会自动进入pdb调试模式。此时你可以使用pdb的命令进行调试,例如:
n:执行下一行代码c:继续执行直到下一个断点q:退出调试器p some_variable:打印某个变量的值
4.结束调试
完成调试后,使用c命令或q命令退出调试模式,测试将继续执行或完全停止。
提示:在进行调试时,确保你已经熟悉了
pdb的基本命令,这样你可以更有效地进行调试。
Feature 文件路径
默认情况下,pytest-bdd 会使用当前模块的路径作为查找 feature 文件的基本路径,但可以在 pytest 配置文件(即pytest.ini、tox.ini 或setup.cfg)中通过在bdd_features_base_dir键中声明新的基本路径来改变这种行为。该路径被解释为相对于 pytest 根目录。你也可以按场景覆盖基本 features 路径,以便覆盖特定测试的路径。
pytest.ini:
[pytest]
bdd_features_base_dir = features/
tests/test_publish_article.py:
from pytest_bdd import scenario
@scenario("foo.feature", "Foo feature in features/foo.feature")
def test_foo():
pass
@scenario(
"foo.feature",
"Foo feature in tests/local-features/foo.feature",
features_base_dir="./local-features/",
)
def test_foo_local():
passfeatures_base_dir参数也可以传递给 @scenario 装饰器。
避免重新输入feature文件名
如果你希望在测试文件中定义场景时避免重新键入 feature 文件名,请使用 functools.partial. 这将使你在测试文件中定义多个场景时变得更加轻松。例如:
# test_publish_article.py的内容
from functools import partial
import pytest_bdd
scenario = partial(pytest_bdd.scenario, "/path/to/publish_article.feature")
@scenario("发表文章")
def test_publish():
pass
@scenario("以未授权用户的身份发表文章")
def test_publish_unprivileged():
pass你可以在 Python 文档中了解有关functools.partial的更多信息。
程序化步骤生成
有时,你的步骤定义会更容易自动化,而不是一遍又一遍地手动编写它们。例如,当使用像pytest-factoryboy这样自动创建 fixture 的库时,这种情况很常见。为每个模型编写步骤定义可能会变得非常繁琐。
为此,pytest-bdd提供了一种自动生成步骤定义的方法。
技巧是将 stacklevel 参数传递给 given, when, then,step 装饰器。这将指示他们将步骤 fixture 注入适当的模块中,而不是仅仅将它们注入调用者框架中。
让我们看一个具体的例子;假设你有一个类 Wallet,其中每种“货币”都有一定数量:
# wallet.py的内容
import dataclass
@dataclass
class Wallet:
verified: bool
amount_eur: int
amount_usd: int
amount_gbp: int
amount_jpy: int
你可以使用 pytest-factoyboy 自动为此类创建模型 fixture:
# wallet_factory.py的内容
from wallet import Wallet
import factory
from pytest_factoryboy import register
class WalletFactory(factory.Factory):
class Meta:
model = Wallet
amount_eur = 0
amount_usd = 0
amount_gbp = 0
amount_jpy = 0
register(Wallet) # 创建 "wallet" fixture
register(Wallet, "second_wallet") # 创建 the "second_wallet" fixture现在我们可以定义一个函数 generate_wallet_steps(...) 来为任何 wallet fixture 创建步骤(在我们的例子中,它将是 wallet 和 second_wallet):
# wallet_steps.py的内容
import re
from dataclasses import fields
import factory
import pytest
from pytest_bdd import given, when, then, scenarios, parsers
def generate_wallet_steps(model_name="wallet", stacklevel=1):
stacklevel += 1
human_name = model_name.replace("_", " ")
@given(f"我有{human_name}", target_fixture=model_name, stacklevel=stacklevel)
def _(request):
return request.getfixturevalue(model_name)
# Generate steps for currency fields:
for field in fields(Wallet):
match = re.fullmatch(r"amount_(?P<currency>[a-z]{3})", field.name)
if not match:
continue
currency = match["currency"]
@given(
parsers.parse(f"我的{human_name}里有{{value:d}}{currency.upper()}"),
target_fixture=f"{model_name}__amount_{currency}",
stacklevel=stacklevel,
)
def _(value: int) -> int:
return value
@then(
parsers.parse(f"我{human_name}里应该有{{value:d}}{currency.upper()}"),
stacklevel=stacklevel,
)
def _(value: int, _currency=currency, _model_name=model_name) -> None:
wallet = request.getfixturevalue(_model_name)
assert getattr(wallet, f"amount_{_currency}") == value
# Inject the steps into the current module
generate_wallet_steps("wallet")
generate_wallet_steps("second_wallet")最后一个文件,wallet_steps.py 现在包含我们的 "wallet" 和 "second_wallet" fixture 的所有步骤定义。
我们现在可以定义这样的场景:
# language: zh-CN
# wallet.feature的内容
功能: 钱包功能
场景: 钱包中的欧元金额保持不变
假如我的第一个钱包里有10欧元
并且我有第一个钱包
那么我第一个钱包里应该有10欧元
场景: 第二个钱包中的英镑金额保持不变
假如我的第二个钱包里有100英镑
并且我有第二个钱包
那么我第二个钱包里应该有100英镑
最后是一个将所有内容组合在一起并运行场景的测试文件:
# contents of test_wallet.py
from pytest_factoryboy import scenarios
from wallet_factory import * # import the registered fixtures "wallet" and "second_wallet"
from wallet_steps import * # import all the step definitions into this test file
scenarios("wallet.feature")钩子函数
pytest-bdd公开了几个pytest钩子,这些钩子可能有助于在其基础上构建有用的报告、可视化等:
pytest_bdd_before_scenario(request, feature, scenario)- 在执行场景之前调用pytest_bdd_after_scenario(request, feature, scenario)- 在执行场景后调用(即使其中一个步骤失败)pytest_bdd_before_step(request, feature, scenario, step, step_func)- 在执行步骤函数并评估其参数之前调用pytest_bdd_before_step_call(request, feature, scenario, step, step_func, step_func_args)- 在使用评估参数执行步骤函数之前调用pytest_bdd_after_step(request, feature, scenario, step, step_func, step_func_args)- 步骤函数成功执行后调用pytest_bdd_step_error(request, feature, scenario, step, step_func, step_func_args, exception)- 当step函数执行失败时调用pytest_bdd_step_func_lookup_error(request, feature, scenario, step, exception)- 当步骤查找失败时调用
测试报告
BDD测试的核心价值之一在于它能够与非技术团队成员清晰地沟通,因此,一个清晰、直观的测试报告对于整个测试过程来说是非常重要的。为此,CukeTest为你提供了内置的多种主题样式的测试报告,确保每当你完成pytest-bdd项目运行时,系统都能为你自动生成一个高品质的测试报告。
值得注意的是,原生的pytest-bdd框架并不直接支持向报告中嵌入文本或图片。为了弥补这一不足,CukeTest对其进行了功能扩展。
报告附件
在pytest-bdd的测试流程中,往往需要为测试报告附加一些额外的信息,例如检查点细节、文本描述、截图或其他关键数据。为了满足这一需求,CukeTest提供了一个特定的功能:request.attach方法,使用户能够在测试步骤中将文本、图像或其他数据以附件形式嵌入到测试报告中。
request是pytest框架的一个特殊对象,它提供了关于当前测试请求的丰富信息。在pytest-bdd的上下文中,通过request对象,我们不仅可以访问当前测试的细节,还可以插入自定义行为,如附加数据到测试报告。
使用方法:
request.attach(target, MIMEType?)参数详解:
- target:
string或Buffer类型,要作为附件的数据内容。 - MIMEType: (可选参数)
string数据类型 - 表示附件的MIME格式。默认格式是text/plain,即纯文本。如果要插入图片,请使用image/png;对于JSON数据,请使用application/json。 - 返回值: 该方法不返回任何内容。
在一个特定的测试步骤中,可以多次调用
request.attach()方法。这样做将允许你在同一步骤中嵌入多个附件。
添加文本附件
文本附件默认采用MIME类型为 text/plain进行存储。然而,你还可以为其指定其他的MIME类型,以适应不同的需求。
添加图像附件
CukeTest允许你以Buffer或base64编码格式将图像嵌入到测试报告中。这种方式特别适用于嵌入测试过程中的屏幕截图或其他相关图片。特别是在使用CukeTest进行桌面应用自动化测试时,每一个控件对象都内置了.takeScreenshot()方法,从而使得你可以轻松地获取控件的截图并作为附件添加到测试报告中,进而帮助团队更好地了解控件的实时状态和行为。
下面的示例展示了如何在测试中嵌入不同类型的附件:
@when(parsers.parse('搜索CukeTest安装路径下的{relative_path}'))
def search_path(get_install_path, relative_path, request):
dest_path = os.path.join(get_install_path, relative_path)
model.getEdit("Edit").set(dest_path)
# 添加文本附件
request.attach(f'目标路径:{dest_path}')
# 添加图片附件
request.attach(model.getList("List").takeScreenshot(), "image/png")
在整个测试执行期间,终端将实时显示脚本的运行信息,这些信息包括剧本、场景以及每个步骤的成功或失败状态。
这种实时反馈不仅为测试人员提供了即时的进度概览,而且在定位和修复潜在问题时起到了关键作用。通过终端输出,测试人员可以迅速地确定哪些步骤成功了,哪些步骤可能遭遇问题,并据此进行后续的分析与调整。
下图展示了一个典型的pytest-bdd测试报告,其中详细列出了各项测试活动的结果:
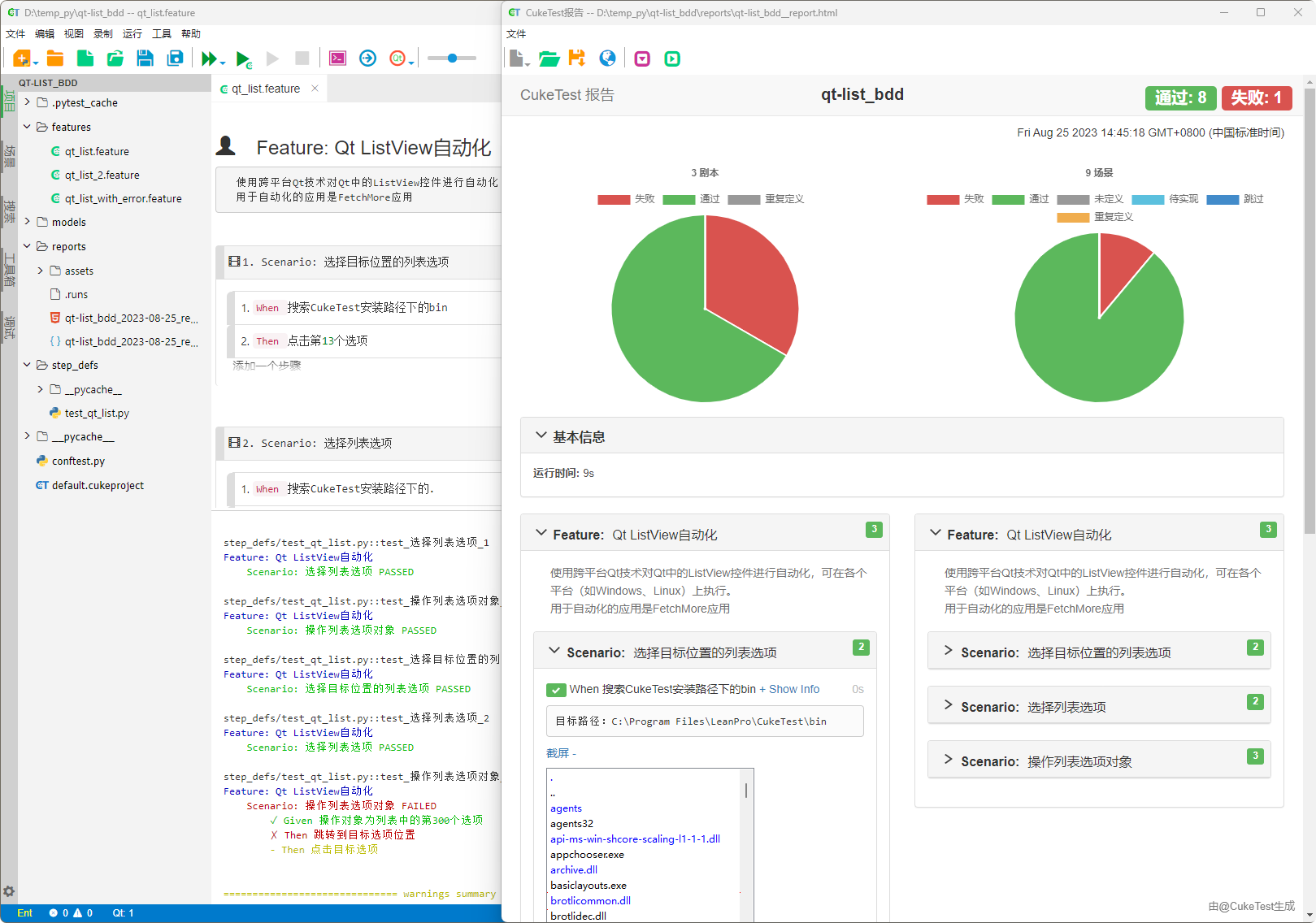
结合图形化的测试报告和终端的实时输出,CukeTest确保你能够全方位地掌握测试流程的每一个细节。这不仅有助于提高测试的准确性,而且在长期的维护和迭代中,能够为团队提供宝贵的参考信息,简化问题定位与修复的流程。
本文基于pytest-bdd的官方文档整理。如需进一步探索或查阅原版英文文档,请前往官方项目页面:https://github.com/pytest-dev/pytest-bdd。