初学者指南:如何使用 Python 开发 BDD 项目

在许多团队的自动化测试实践中,经常会遇到一个矛盾:测试代码需要在持续集成环境中可靠运行,但同时业务人员也希望能直观地理解测试的内容。常见的情况是,用例文档里写着预期行为,而测试代码另起炉灶;或者测试代码实现得很细致,却难以被非技术同事读懂。行为驱动开发(BDD, Behavior Driven Development)就是为了解决这一问题而提出的。它通过接近自然语言的方式来描述软件的行为,再把这些描述与自动化测试绑定,从而既能支撑业务沟通,又能真正落地执行。本文将以 Python 生态中的 pytest-bdd 为例,带你从零开始搭建一个可运行的 BDD 项目。
1. pytest-bdd 简介
pytest-bdd 是构建在 pytest 之上的一个插件,它把 Gherkin 语法(一种类似自然语言的描述方式,常用于 Cucumber 等 BDD 框架)中的 Given、When、Then 关键字与 pytest 的运行机制和 fixture 系统结合起来。
- 在中文环境中,
Given/When/Then通常分别对应假如/当/那么,这让测试场景更贴近中文表达。- feature 文件:用来保存基于 Gherkin 语法编写的测试场景,后缀为
.feature。- fixture:pytest 的一种机制,用于准备测试所需的依赖、数据或环境,可以在多个用例中复用。
使用 pytest-bdd 时,不需要额外的运行器,所有测试仍通过 pytest 执行。这意味着单元测试、集成测试和 BDD 测试可以共存于同一个项目和流水线中。同时,你还可以继续复用 pytest 的 fixture 注入机制,把数据准备和环境初始化统一管理起来。更重要的是,那些用自然语言编写的 feature 文件不仅是测试用例,也是项目的“活文档”,能够在业务人员、测试人员和开发人员之间搭建沟通的桥梁。
这种方式的价值在于:
- 统一入口:所有类型的测试都用
pytest启动,减少持续集成(CI)的配置工作; - fixture 复用:前置条件与数据准备逻辑集中管理,避免重复,提高可维护性;
- 自然语言即文档:feature 文件既是测试用例,也是业务需求的直观表达,方便业务人员和技术人员基于同一份文档开展协作。
2. 搭建一个 BDD 项目
2.1 目录结构
一个典型的 pytest-bdd 项目会把 feature 文件、步骤实现和公共资源分门别类地放置。例如,可以建立一个 features 文件夹专门保存 Gherkin 场景,一个 steps 文件夹保存与场景对应的 Python 测试代码,同时准备一个 common_steps.py 文件用来放置通用步骤,conftest.py 则存放 fixture、全局配置和钩子函数,最后用 pytest.ini 来集中声明一些配置,如 feature 根目录和标记定义。这样的组织方式能让目录清晰,后续扩展时也更容易维护。
project_name/
├── features/
│ └── publish_article.feature # Gherkin 文件(.feature)
├── steps/
│ └── test_publish_article.py # 步骤实现(测试代码)
├── common_steps.py # 公共步骤(建议独立模块)
├── conftest.py # fixture、全局配置、hooks
└── pytest.ini # 可选:BDD 基础路径、markers 等小提示:
pytest.ini可以设置bdd_features_base_dir,让 pytest 自动从指定目录查找 feature 文件。
2.2 编写第一个场景
在 BDD 项目 中,feature 文件是核心。它使用 Gherkin 语言描述功能点和行为,每个文件通常只关注一个独立的功能,并包含若干具体场景。
下面以“博客文章发布”为例,展示一个最小化的场景定义:
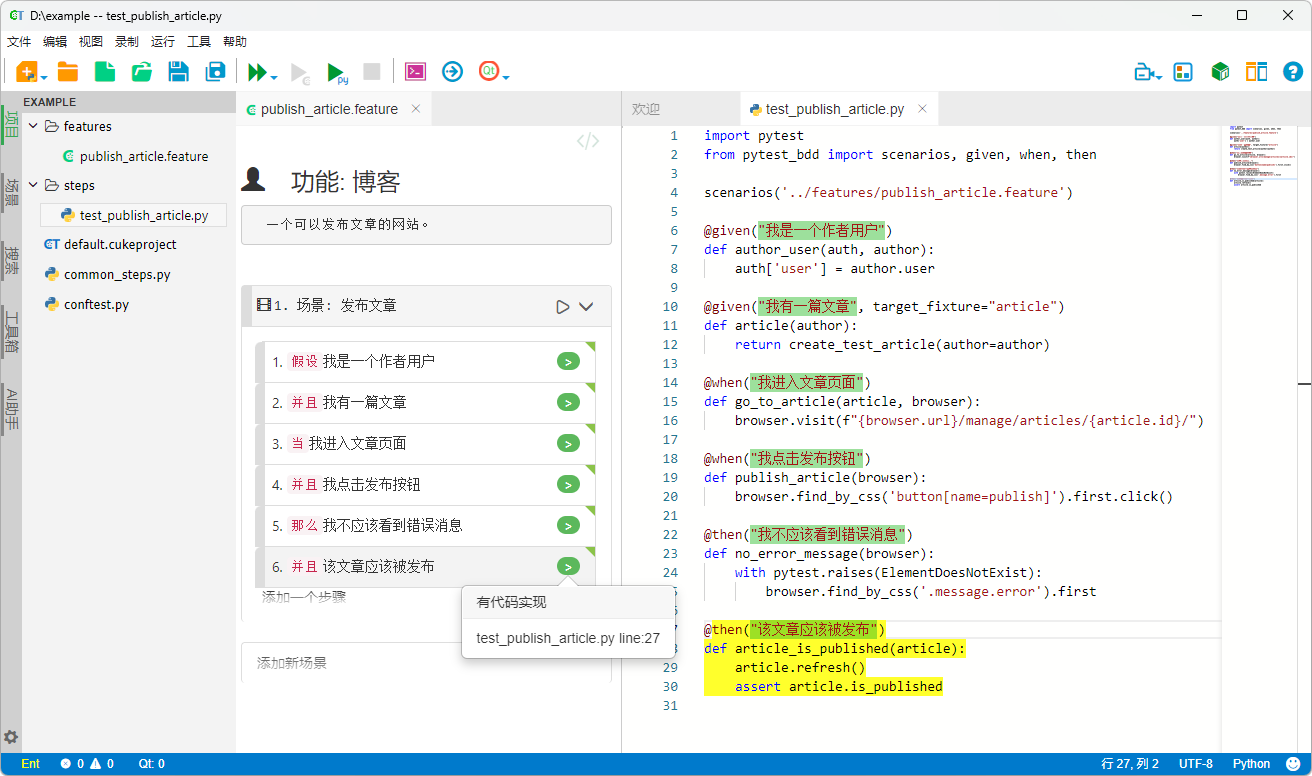
project_name/features/publish_article.feature:
# language: zh-CN
功能: 博客
一个可以发布文章的网站。
场景: 发布文章
假设我是一个作者用户
并且我有一篇文章
当我进入文章页面
并且我点击发布按钮
那么我不应该看到错误消息
并且该文章应该被发布建议每个
.feature文件只描述一个核心功能,这样既便于阅读,也方便长期维护。
2.3 定义步骤函数
写好场景文件后,需要把自然语言的描述和实际的 Python 实现关联起来。这是通过步骤函数完成的。pytest-bdd 提供了 @given、@when、@then 这些装饰器,用来将场景中的文字绑定到具体的代码逻辑。
steps/test_publish_article.py:
import pytest
from pytest_bdd import scenarios, given, when, then
scenarios('../features/publish_article.feature')
@given("我是一个作者用户")
def author_user(auth, author):
auth['user'] = author.user
@given("我有一篇文章", target_fixture="article")
def article(author):
return create_test_article(author=author)
@when("我进入文章页面")
def go_to_article(article, browser):
browser.visit(f"{browser.url}/manage/articles/{article.id}/")
@when("我点击发布按钮")
def publish_article(browser):
browser.find_by_css('button[name=publish]').first.click()
@then("我不应该看到错误消息")
def no_error_message(browser):
with pytest.raises(ElementDoesNotExist):
browser.find_by_css('.message.error').first
@then("该文章应该被发布")
def article_is_published(article):
article.refresh()
assert article.is_published在这里,scenarios() 会自动加载并绑定 feature 文件中的所有场景,也可以指向整个目录以批量加载。每个步骤函数通过装饰器与自然语言对应,负责实现具体的业务逻辑。如果需要在场景中覆盖或产出 fixture,可以使用 target_fixture 参数;而像 auth、browser 这样的共享前置条件,通常会写在 conftest.py 中,方便多个测试文件共享。这样,一个最小可运行的 BDD 测试就完成了。
3. 语法与复用技巧
在编写 BDD 测试时,随着场景和步骤的增多,往往会遇到重复、冗长或可维护性不佳的问题。pytest-bdd 提供了一些语法和复用技巧,可以让用例更紧凑、更灵活,也更符合自然语言的表达习惯。
3.1 别名与星号
同一个操作可能有不同的表述方式。为了避免重复实现,我们可以为同一个步骤函数添加多个别名,让它同时匹配不同的语句。这不仅减少了代码量,也使场景描述更自然。例如,下面的步骤函数既可以匹配“我有一篇文章”,也可以匹配“有一篇文章”:
@given("我有一篇文章")
@given("有一篇文章")
def article(author):
return create_test_article(author=author)在场景中,连续出现的 假如、当、那么 等关键字也可能显得冗余。pytest-bdd 允许使用星号 * 来代替,它会自动继承前一个关键字,从而让描述更加紧凑,读起来更像自然语言。例如:
场景: 我是作者
假如我是一个作者
* 我有一篇文章
* 我有一支笔这种写法既减少了重复,又让场景更接近故事叙述。
3.2 参数化步骤与解析器
许多业务逻辑涉及不同数字或字符串的变化,如果为每种情况单独写一个步骤,代码会迅速膨胀。为了解决这个问题,pytest-bdd 提供了多种解析器(如 parsers.parse、parsers.re、parsers.cfparse),可以直接在步骤文本中提取参数,并完成类型转换。这样,同一个步骤函数就能处理不同的输入,使测试更加灵活。
例如,下面的场景描述了逐步吃掉黄瓜的过程:
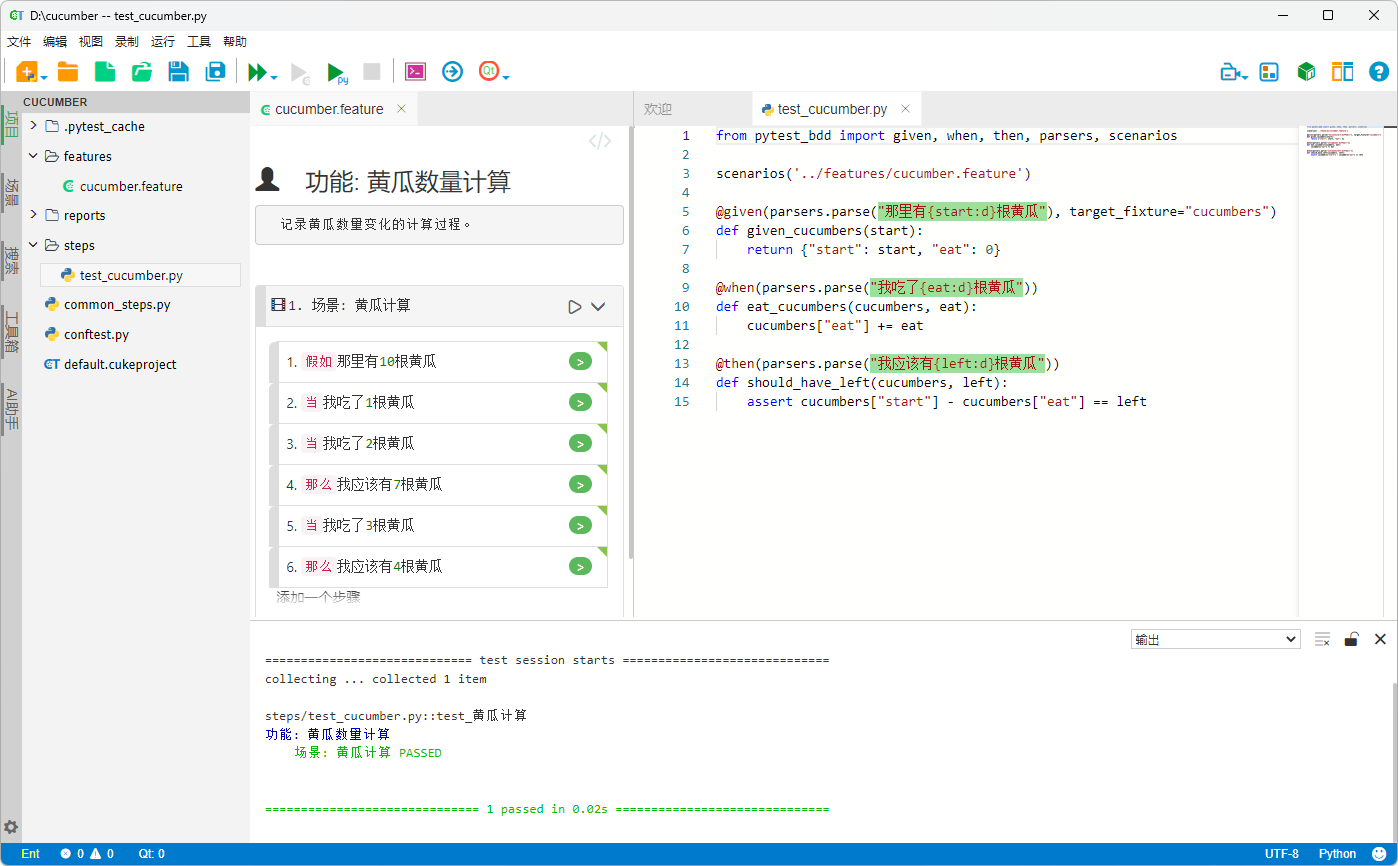
场景: 黄瓜计算
假如那里有10根黄瓜
当我吃了1根黄瓜
当我吃了2根黄瓜
那么我应该有7根黄瓜
当我吃了3根黄瓜
那么我应该有4根黄瓜对应的实现中,参数 {start:d}、{eat:d} 和 {left:d} 会自动被解析为整数,而不是普通字符串:
from pytest_bdd import given, when, then, parsers
@given(parsers.parse("那里有{start:d}根黄瓜"), target_fixture="cucumbers")
def given_cucumbers(start):
return {"start": start, "eat": 0}
@when(parsers.parse("我吃了{eat:d}根黄瓜"))
def eat_cucumbers(cucumbers, eat):
cucumbers["eat"] += eat
@then(parsers.parse("我应该有{left:d}根黄瓜"))
def should_have_left(cucumbers, left):
assert cucumbers["start"] - cucumbers["eat"] == left通过这种方式,我们避免了为不同数值重复编写相同逻辑,使得测试代码更简洁,场景也更易于扩展。
3.3 场景大纲、数据表、文档字符串
在实际编写测试时,除了基本的场景以外,pytest-bdd 还支持更灵活的结构。场景大纲允许我们通过模板化的写法覆盖多组用例,只需在步骤中用尖括号包裹的变量(如 <var>)来表示不同的数据。通过在示例表中提供多组输入和输出,就能一次性生成多个测试场景。示例表还可以定义多个,并结合标签进行筛选,从而在一次执行中区分正向和负向用例。下面是一个简单的场景大纲示例:
场景大纲: 黄瓜计算
假如那里有<start>根黄瓜
当我吃了<eat>根黄瓜
那么我应该有<left>根黄瓜
例子:
| start | eat | left |
| 12 | 5 | 7 |
| 11 | 5 | 6 |
| 13 | 5 | 8 |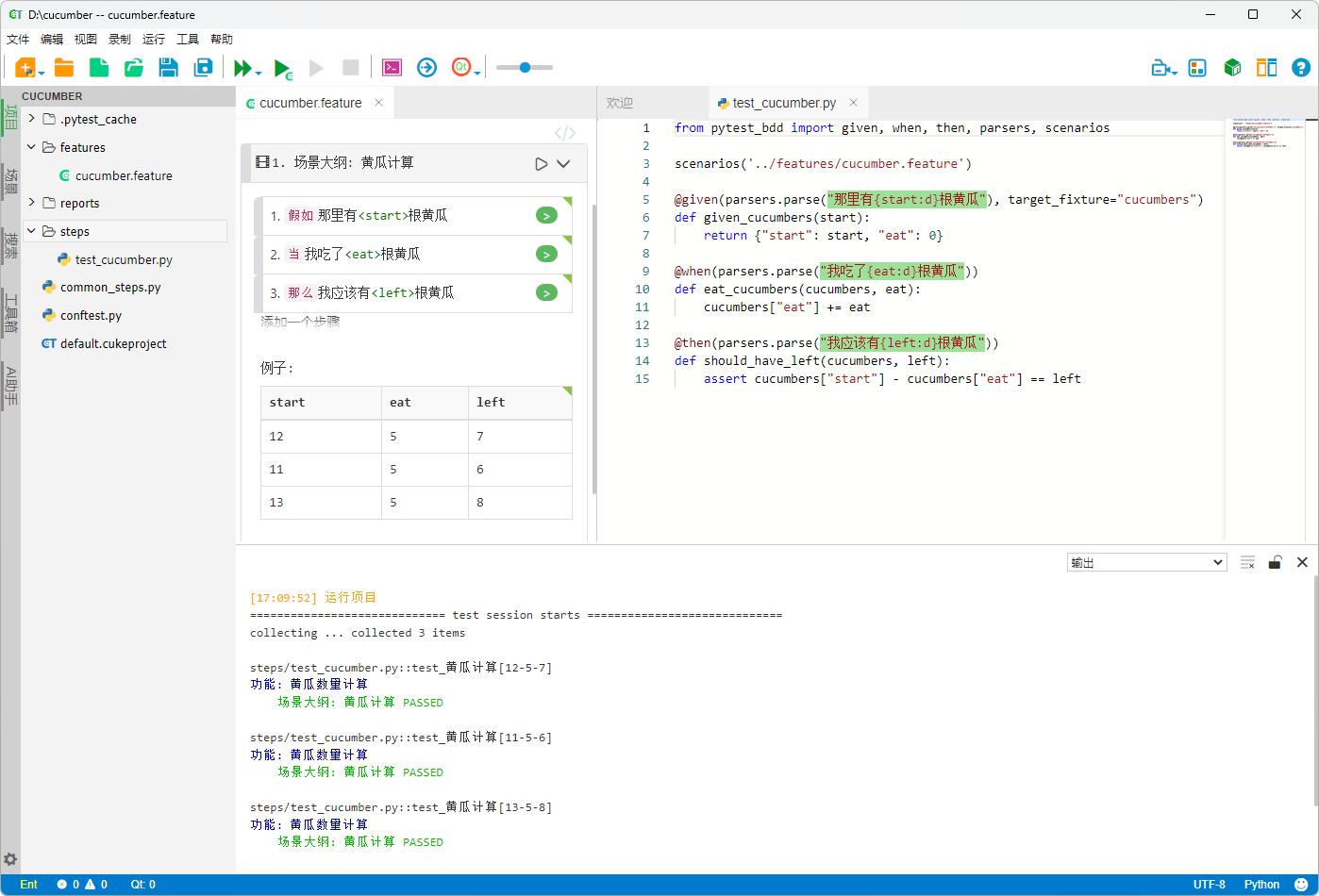
在需要批量输入或批量断言的场景中,可以直接在步骤里使用数据表。它以二维表格的形式组织输入数据,每一行表示一组数据,代码中可通过 datatable 参数按行读取并处理。例如,下面的用例展示了如何在一个步骤里创建多个用户,并在后续断言这些用户都能登录系统:
场景: 批量创建用户
假如我创建以下用户:
| name | email |
| alice | alice@test.com |
| bob | bob@test.com |
那么这些用户都应该能登录系统from pytest_bdd import given, then
@given("我创建以下用户:", target_fixture="users")
def create_users(datatable):
headers = datatable[0]
return [dict(zip(headers, row)) for row in datatable[1:]]
@then("这些用户都应该能登录系统")
def all_users_can_login(users):
for u in users:
assert login(u["name"], u["email"]) is True除了表格,pytest-bdd 还支持文档字符串(docstring),它以多行字符串的方式向步骤传递内容。写法上只需用三引号括起来,缩进与换行会被自动规范化。常见的使用场景是传递较长的文本,例如一篇文章的标题和正文:
场景: 发布文章
假如我有以下文章内容:
"""
标题: pytest-bdd 教程
正文: 使用 CukeTest 写 BDD 测试非常方便。
"""
当我提交文章
那么系统应该保存成功from pytest_bdd import given, when, then
@given("我有以下文章内容:", target_fixture="article")
def article(docstring):
title, body = docstring.strip().split("\n", 1)
return {"title": title.replace("标题: ", ""), "body": body.replace("正文: ", "")}
@when("我提交文章")
def submit_article(article):
save_article(article)
@then("系统应该保存成功")
def check_saved(article):
assert is_article_saved(article["title"])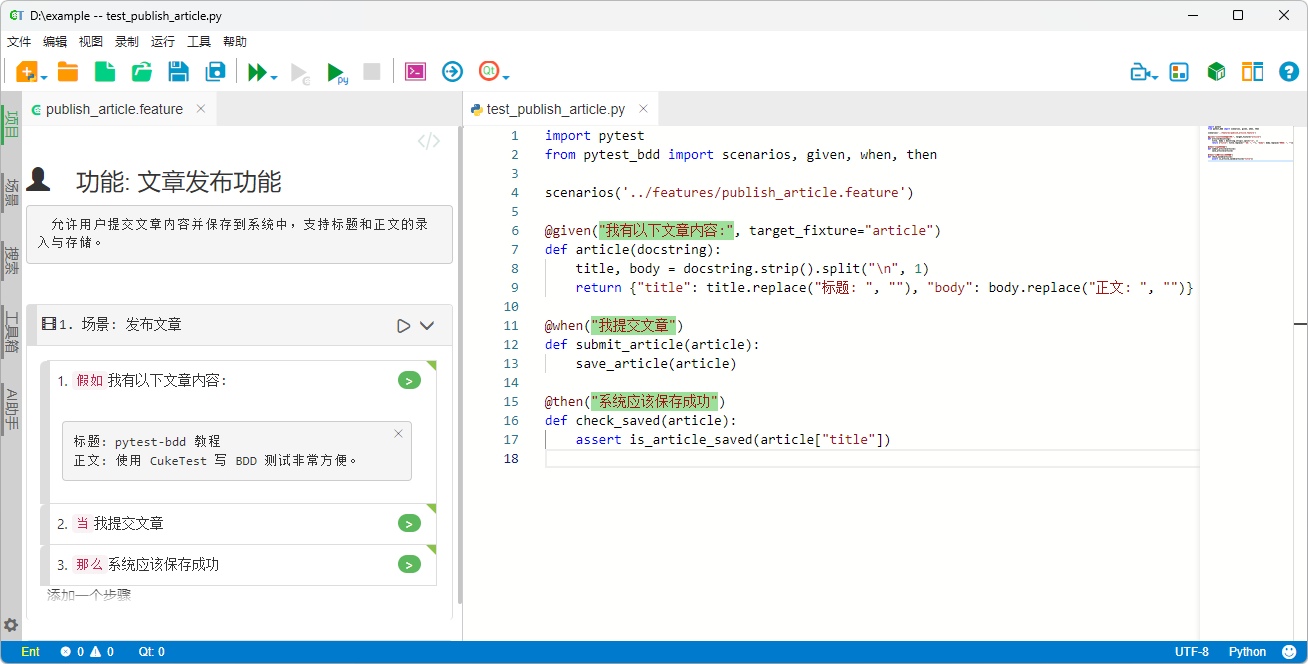
3.4 背景与标签
在一个功能下,往往会有多个场景需要共享相同的前置条件。此时可以使用 背景(Background) 来抽取公共步骤。背景中的内容会在每个场景执行前自动运行,从而避免重复书写。这些步骤只允许使用 Given,语义上强调“让系统进入一个已知状态”。例如,用户登录功能中,系统启动和数据库清空就是所有场景的前提条件,可以统一放在背景部分,而后续的“成功登录”与“登录失败”两个场景则分别表达不同的逻辑分支。
# language: zh-CN
功能: 用户登录
背景:
假如系统已启动
假如数据库已清空
场景: 成功登录
假如我是注册用户 "alice"
当我使用账号 "alice" 和密码 "123456" 登录
那么登录应当成功
场景: 登录失败
假如我是未注册用户 "bob"
当我使用账号 "bob" 和密码 "654321" 登录
那么登录应当失败除了背景,标签(Tags) 也是组织用例的重要手段。在 pytest-bdd 中,标签与 pytest 的 markers 完全互通。标签既可以标记在功能(Feature)层面,也可以标记在场景(Scenario)或场景大纲(Scenario Outline)的例子(Examples)层面。这样,测试人员便能通过标签来选择性运行某些场景,或者对用例集进行分组管理。下面的示例展示了如何在不同层级使用标签:功能层面使用 @backend,场景层面使用 @smoke、@regression,而在场景大纲的例子中又使用 @happy_path 和 @edge_case 来区分不同的数据组。
下面的示例展示了不同级别的标签:
# language: zh-CN
@backend
功能: 用户登录功能
用不同角色的账号验证登录逻辑
@smoke
场景: 管理员成功登录
假如我是管理员用户
当我输入正确的密码
那么我应该能登录成功
@regression
场景: 普通用户登录失败
假如我是普通用户
当我输入错误的密码
那么我应该看到错误提示
@outline
场景大纲: 多角色登录
假如我是<role>
当我输入<password>密码
那么登录结果应该是<result>
@happy_path
例子: 正常账号
| role | password | result |
| 作者 | 正确 | 成功 |
| 编辑 | 正确 | 成功 |
@edge_case
例子: 异常账号
| role | password | result |
| 作者 | 错误 | 失败 |
| 游客 | 任意 | 失败 |运行时可以通过 pytest -m 的参数来组合筛选。例如:
pytest -m backend:执行所有带有backend的场景(即整个 feature 文件下所有场景)pytest -m regression:只执行“普通用户登录失败”场景pytest -m "happy_path or regression":执行正常账号例子 + 普通用户登录失败场景pytest -m "not happy_path":执行除正常账号外的所有测试
借助这种机制,就能灵活地控制不同测试集的运行范围。
4. 运行、组织与扩展
4.1 一键收集全部场景
随着用例数量的增长,逐个在测试文件里绑定场景会变得冗长。此时,可以使用 scenarios() 方法来自动收集并绑定场景。给定一个路径,它会递归地加载其中的 feature 文件,实现一键绑定。你可以传入整个目录路径,也可以传入单个 feature 文件路径,从而根据需要灵活选择。
from pytest_bdd import scenarios
# 递归绑定整个目录
scenarios("../features")
# 仅绑定单个文件
scenarios("../features/some_feature.feature")4.2 用 conftest 管理 fixture,用独立模块管理公共步骤
在组织测试代码时,推荐把 fixture、钩子和全局配置放在 conftest.py 文件里,用于统一管理环境准备、依赖对象和清理逻辑;而通用的步骤函数则放在独立的模块(如 common_steps.py),在需要的测试文件中通过导入来复用。这种方式可以避免 conftest.py 过于臃肿,同时让步骤逻辑得到清晰复用。
示例:conftest.py
import pytest
@pytest.fixture
def browser():
# 初始化浏览器或客户端
yield Browser()
# 结束清理common_steps.py
from pytest_bdd import given, when, then
@given("系统已启动")
def system_started():
return {"status": "running"}
@when("我访问控制台")
def open_dashboard(browser):
browser.goto("/dashboard")
@then("我应该看到欢迎页面")
def should_see_welcome(browser):
assert "欢迎" in browser.text()steps/test_dashboard.py
from pytest_bdd import scenarios
from common_steps import * # 导入公共步骤
scenarios("../features/dashboard.feature")4.3 钩子函数(Hooks)
pytest-bdd 提供了丰富的钩子函数,可以在场景或步骤的不同阶段插入逻辑。例如,可以在场景执行前打印提示信息,在场景执行后记录结果。对于必须执行的清理行为,建议放在 fixture 的 finalizer 或合适的钩子中,而不是放在场景的最后一个步骤里,避免因步骤失败而导致清理被跳过。
# conftest.py
def pytest_bdd_before_scenario(request, feature, scenario):
print(f"准备执行场景: {scenario.name}")
def pytest_bdd_after_scenario(request, feature, scenario):
print(f"完成场景: {scenario.name}")5. 使用 CukeTest 开发 BDD 项目
当你已经能熟练使用 pytest-bdd 编写和运行测试时,可能会希望在一个集成环境中完成建项目、写步骤、运行与生成报告等操作。CukeTest 针对 pytest-bdd 提供了完整的支持,例如步骤与代码之间的双向跳转、对缺失步骤自动生成函数框架、基于标签的运行过滤,以及多种主题的测试报告。这些功能能够减少重复操作,让你把更多精力放在用例逻辑上。
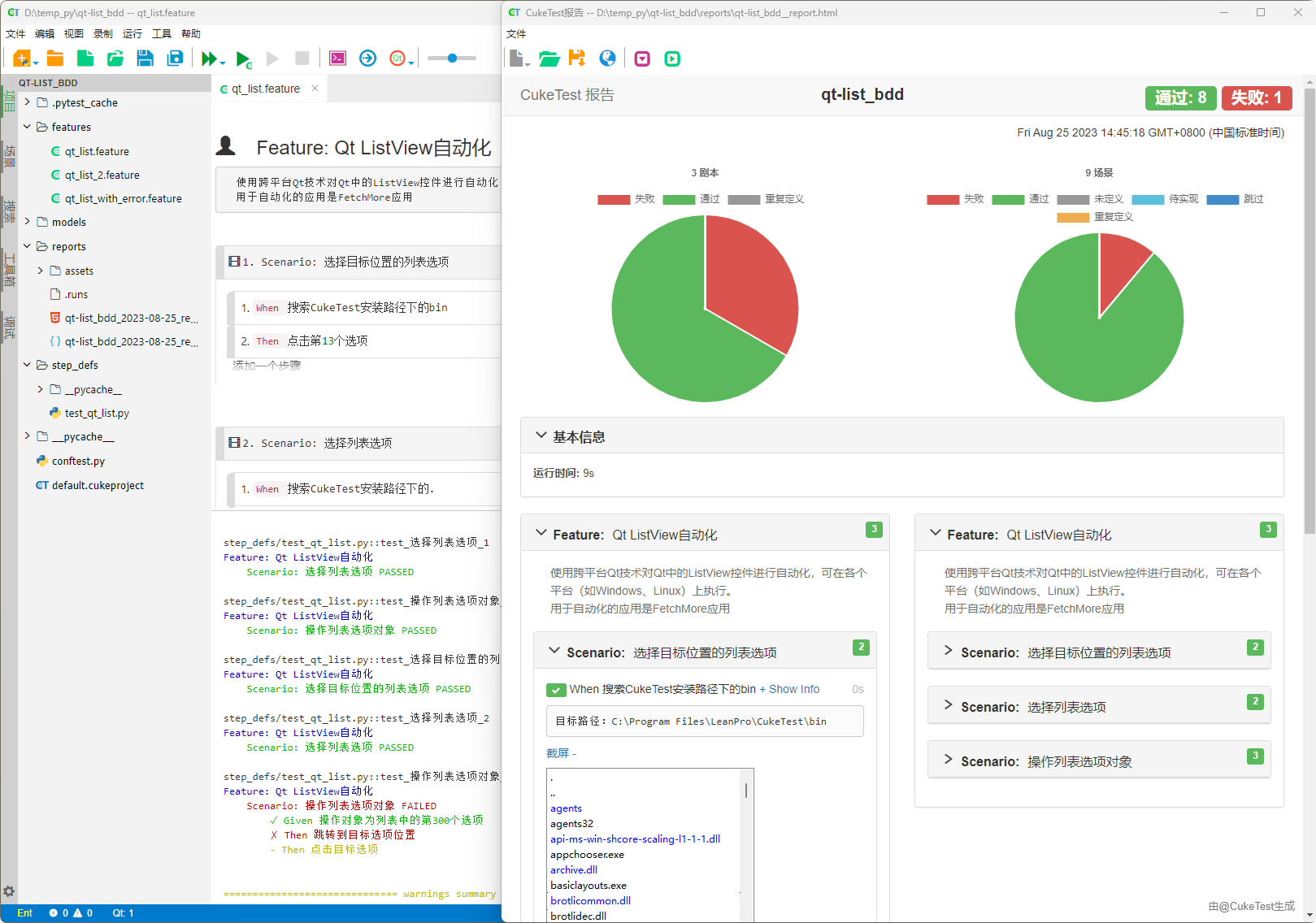
不过,CukeTest 的价值并不局限于对 BDD 的支持。它本身就是一个功能全面的自动化测试工具,覆盖 Web、桌面(Windows、Qt、Java、Linux)、移动、API、图像识别与 OCR 等多种类型的自动化需求,并能运行在 Windows、Linux、Mac 以及国产操作系统上,支持不同的 CPU 架构。同时,它还内置了 AI 助手,能够帮助生成用例、分析报告和准备测试数据。这使得团队可以在同一个工具中完成更复杂的端到端自动化测试。
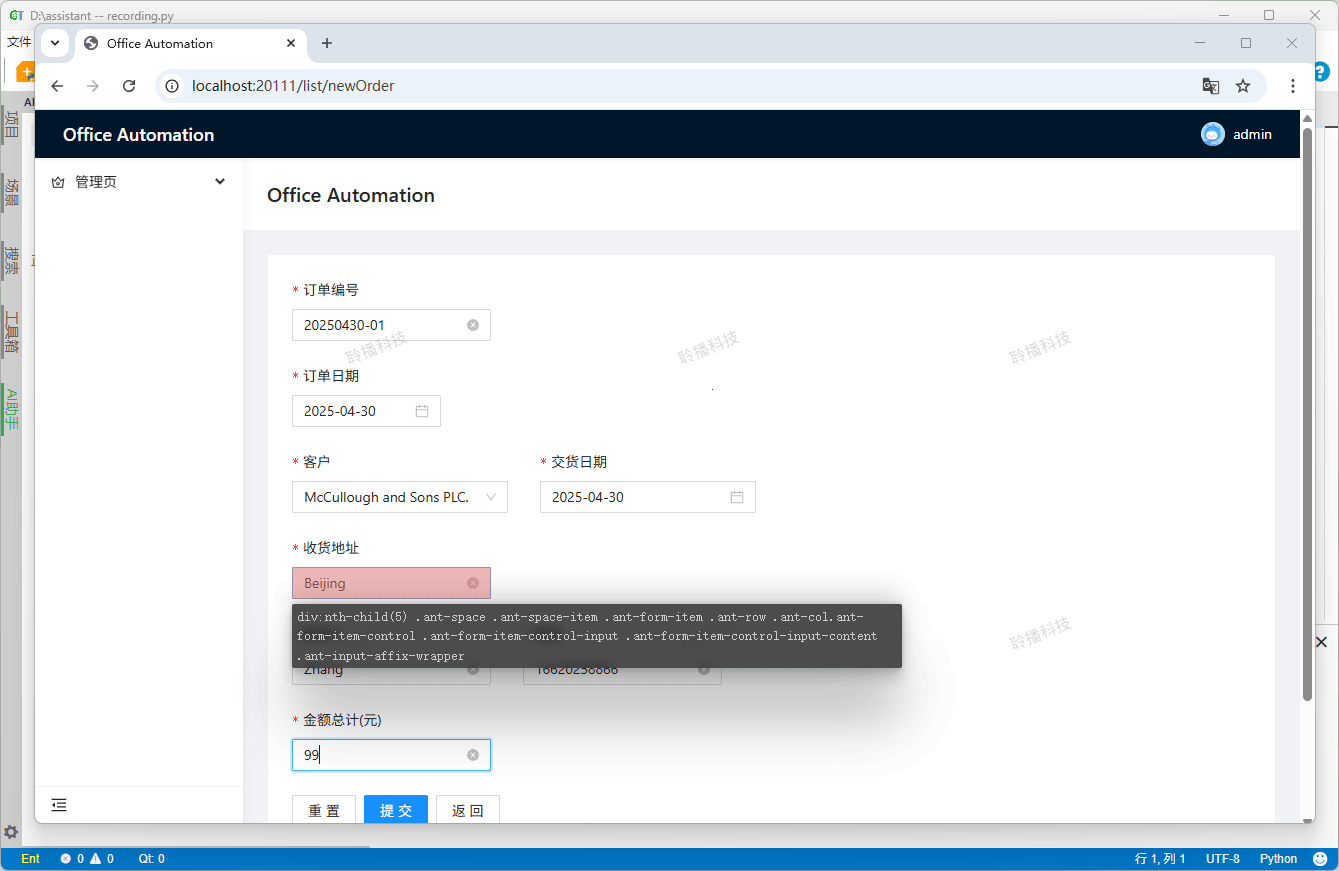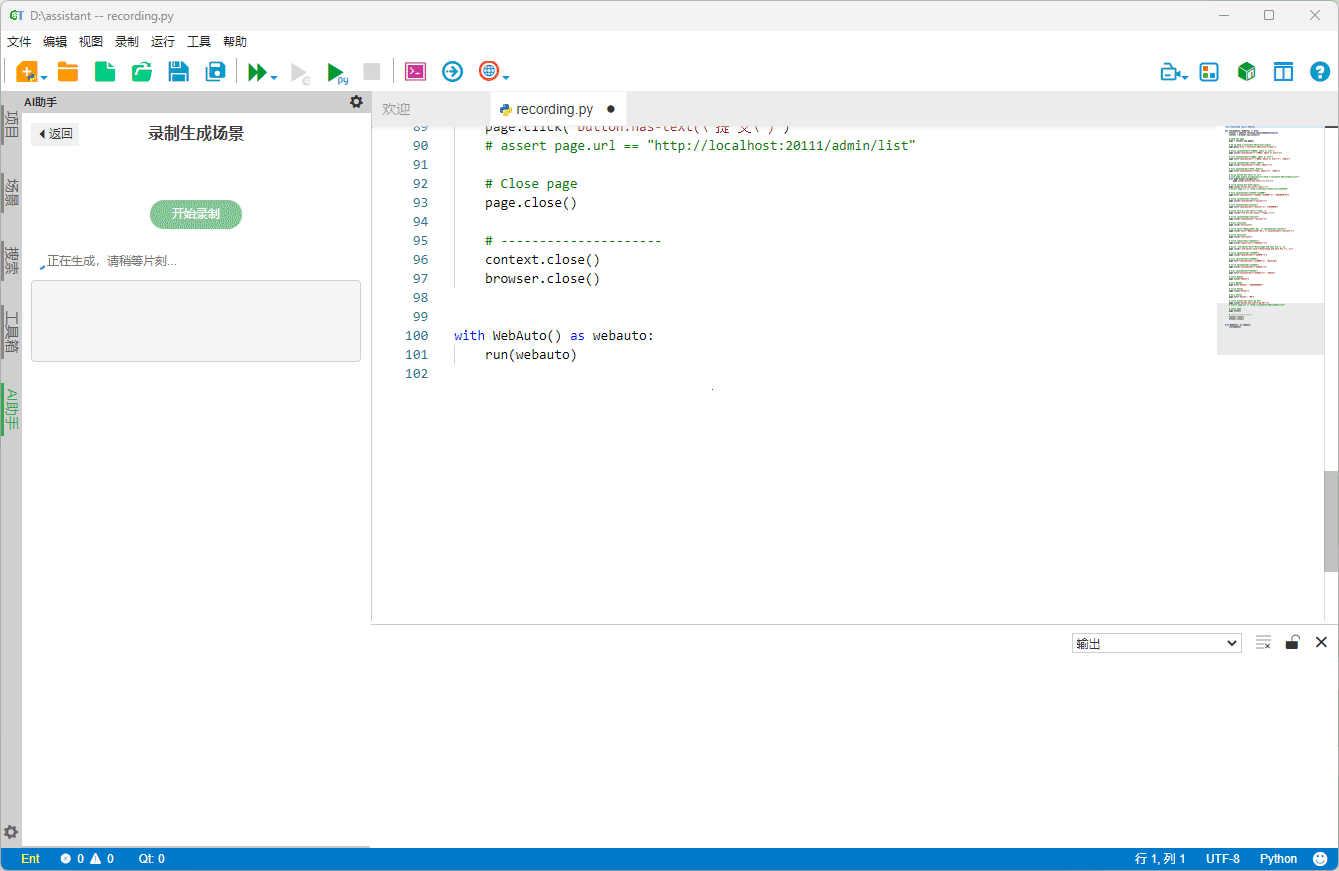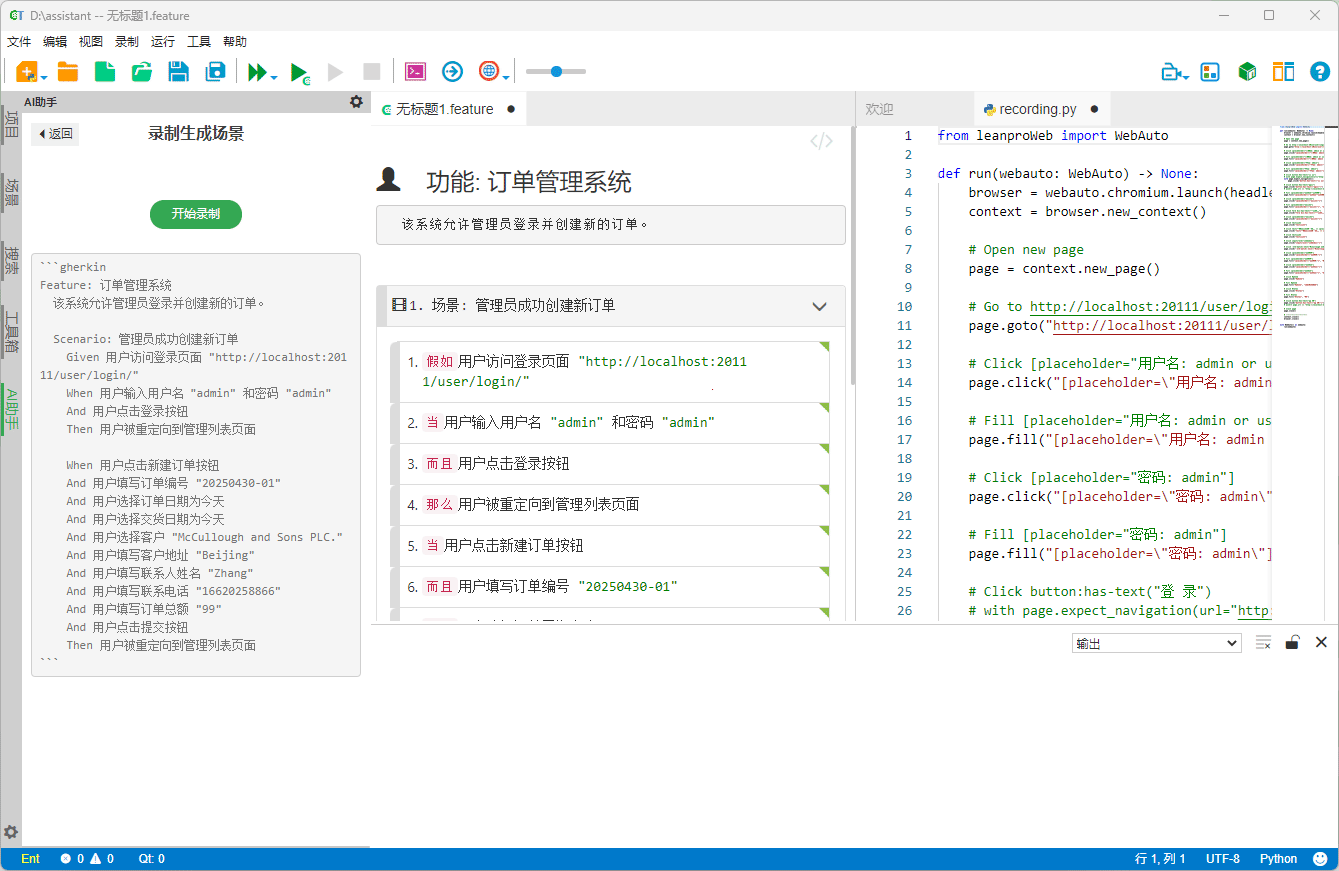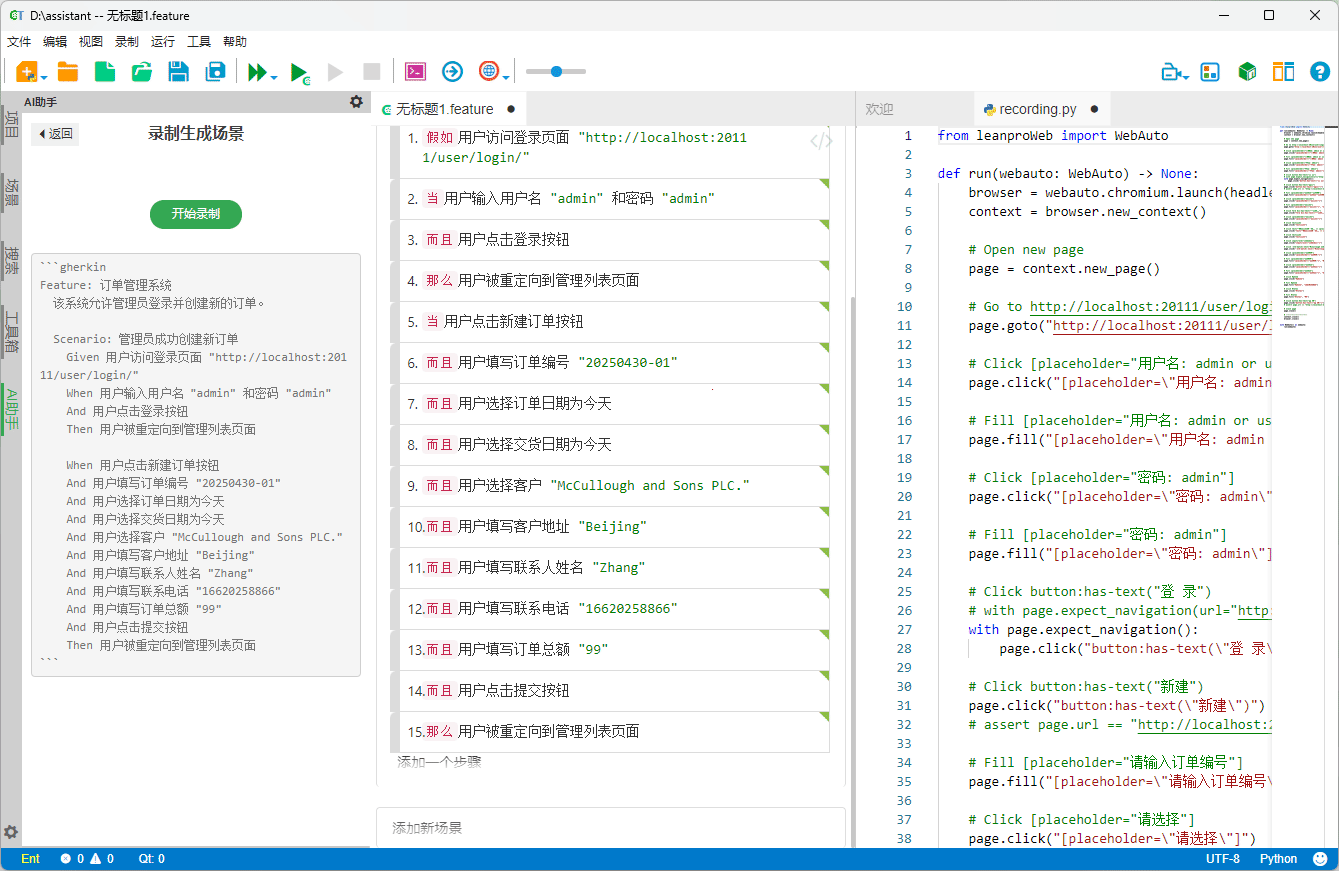
6. 组织大型用例集的实用指南
当测试规模扩展到较大范围时,合理的结构与组织方式比工具本身更为重要。实践中常见的做法包括:
按模块或业务线拆分 feature 文件 将不同业务功能分别写在各自的
.feature文件中,例如区分前端、后端或不同业务线。运行时再通过标签(markers)选择需要的部分。这能让文件更清晰,也便于团队分工。公共步骤集中管理 将通用的
Given/When/Then步骤放在一个或多个 Python 模块(如common_steps.py),在需要的测试文件中通过导入来复用。保证每个场景独立可运行 设计时尽量不让场景相互依赖。这样便于单独复现与调试,也减少“前序失败引发连锁”的影响。
从小规模开始 不要一开始就写很大的用例集。先写少量 feature 与场景,逐步扩展,便于及时调整结构与命名。
善用标签(tags/markers) 为场景与功能添加如
@smoke、@regression的标签,组合表达式可灵活筛选执行集。利用工具辅助 结合 IDE 与框架工具(如 CukeTest 的步骤生成/报告附件等)减少重复工作,把时间花在用例质量上。
7. 结语
pytest-bdd 让团队能够以直观且可执行的方式描述业务行为,同时充分利用 pytest 的生态和工程化能力。在此基础上,如果需要更丰富的界面自动化、跨平台支持和 AI 能力,CukeTest 可以作为统一的平台补齐这些能力,并为 pytest-bdd 的创建与运行提供额外的支持。这样,团队既能保证测试的可读性和协作性,也能在复杂的业务场景中实现高效的自动化。
延伸阅读:Pytest-BDD 使用指南